FLUCCS - Using Code and Change Metrics to Improve Fault Localization
This page is supplementary to the paper entitled "FLUCCS: Using Code and Change Metrics to Improve Fault Localization", which has been presented at the International Symposium on Software Testing and Analysis 2017. This page contains additional results that could not be reported in the paper due to page limits.
Background
Fault localization aims to support the debugging activities of human developers by highlighting the program elements that are suspected to be responsible for the observed failure. Spectrum Based Fault Localization (SBFL), an existing localization technique that only relies on the coverage and pass/fail results of executed test cases, has been widely studied but also criticized for the lack of precision and limited effort reduction. To overcome restrictions of techniques based purely on coverage, we extend SBFL with code and change metrics that have been studied in the context of defect prediction, such as size, age and code churn. Using suspiciousness values from existing SBFL formulas and these source code metrics as features, we apply two learn-to-rank techniques, Genetic Programming (GP) and linear rank Support Vector Machines (SVMs). We evaluate our approach with a ten-fold cross validation of method level fault localization, using 386 real world faults from the Defects4J repository. GP with additional source code metrics ranks the faulty method at the top for 144 faults, and within the top ten for 304 faults. This is a significant improvement over the state-of-the-art SBFL formulas, the best of which can rank 65 and 212 faults at the top and within the top ten, respectively.
Distribution of Wasted Effort
Our objective is to minimize the effort wasted looking at the non-faulty program elements. We use wasted effort (wef), the absolute count version of the traditional Expense metric. Following histograms describe the overall distribution of wef.
These histograms show the distribution of wef values per project. Distribution of wef values for both median and the best performance GP-generated ranking models, denoted as 'med' and 'min' respectively, are shown side by side in these histograms.
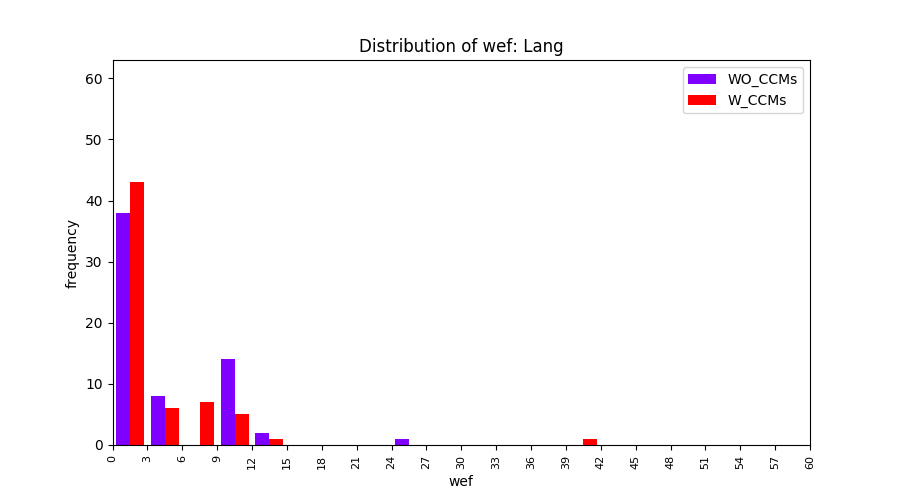
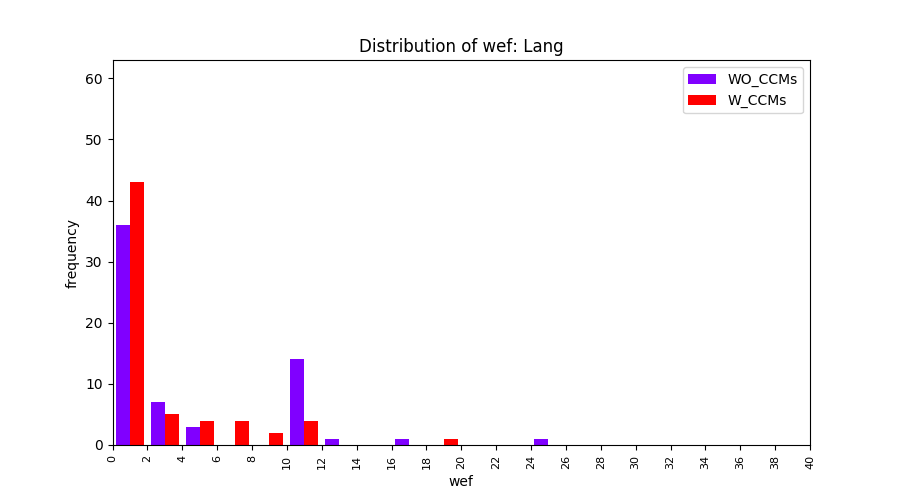
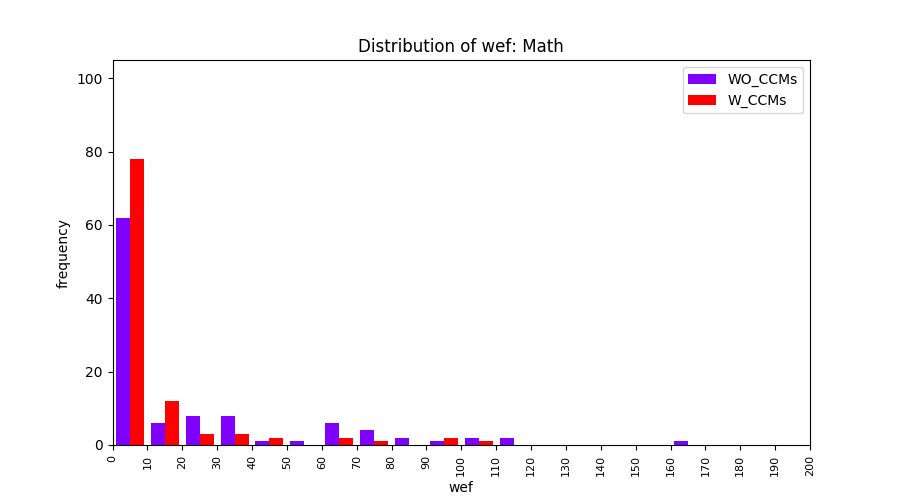
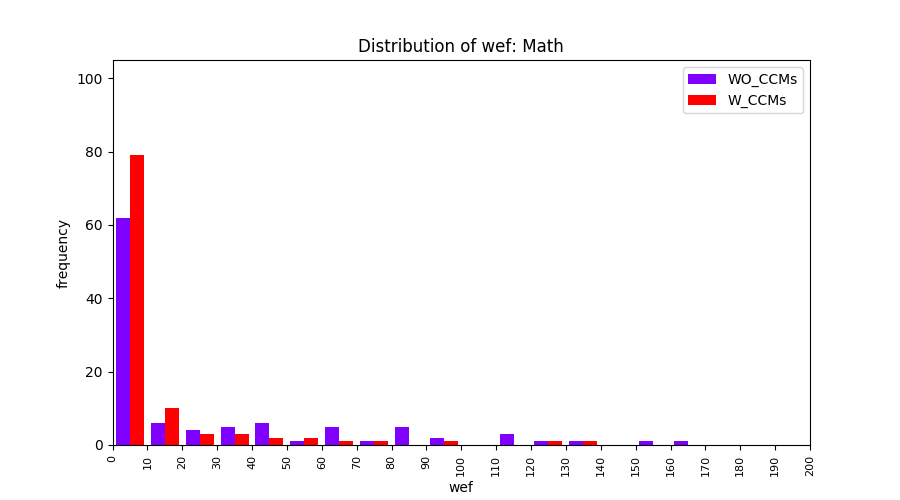
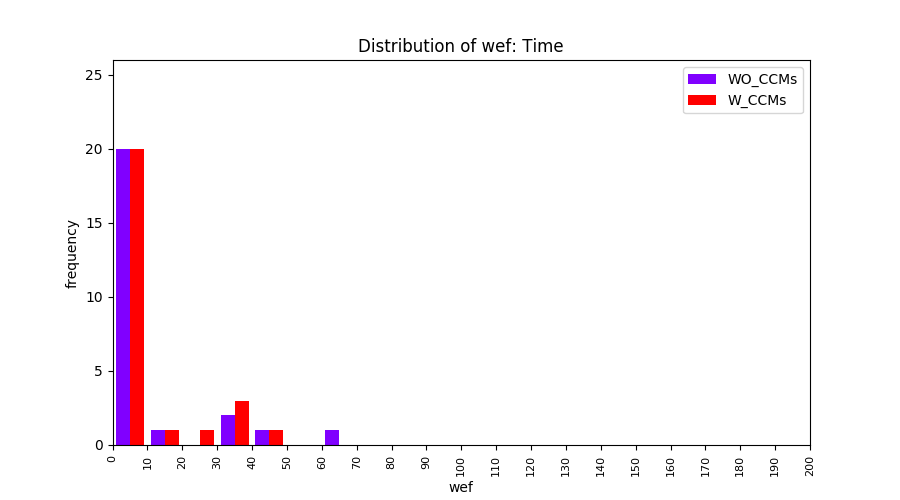
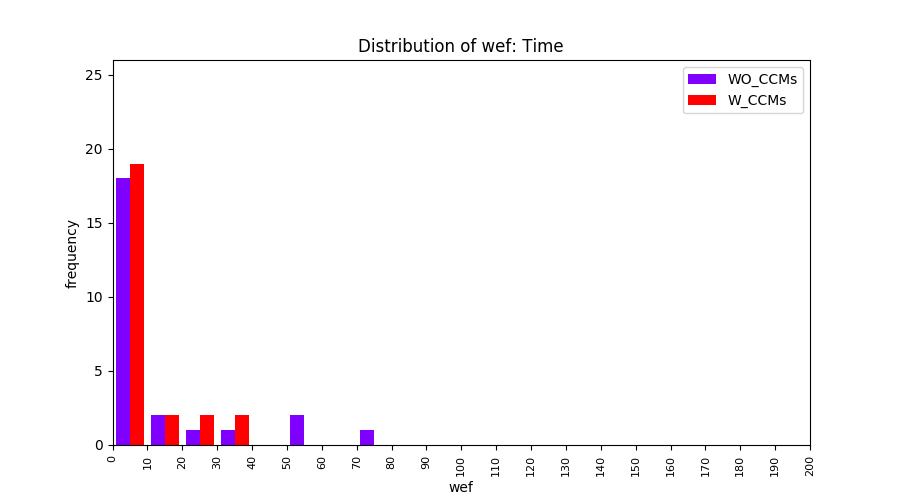
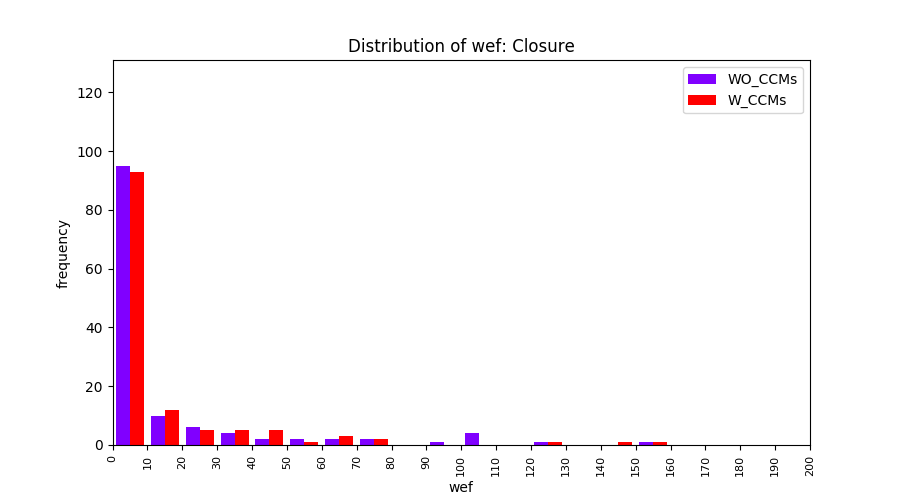
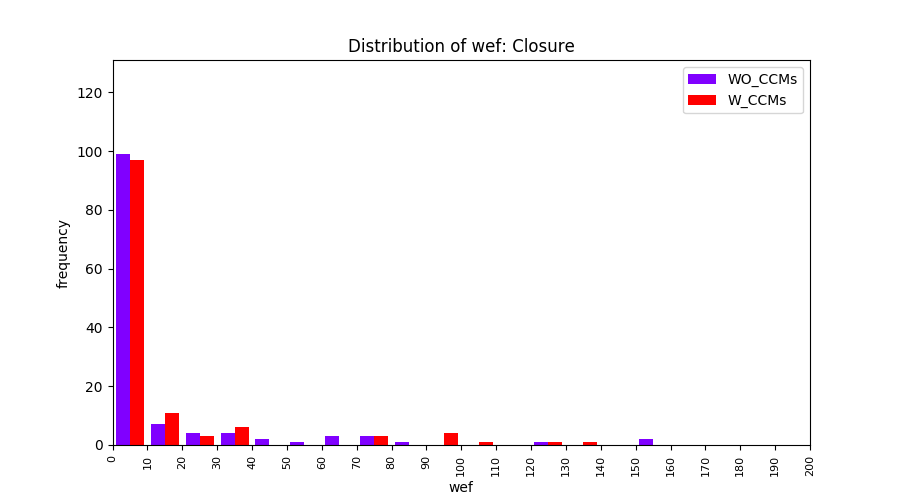
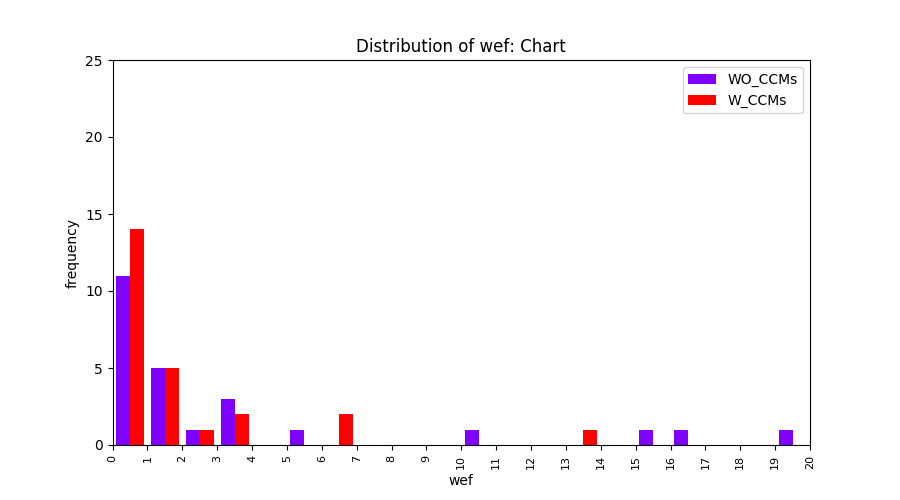
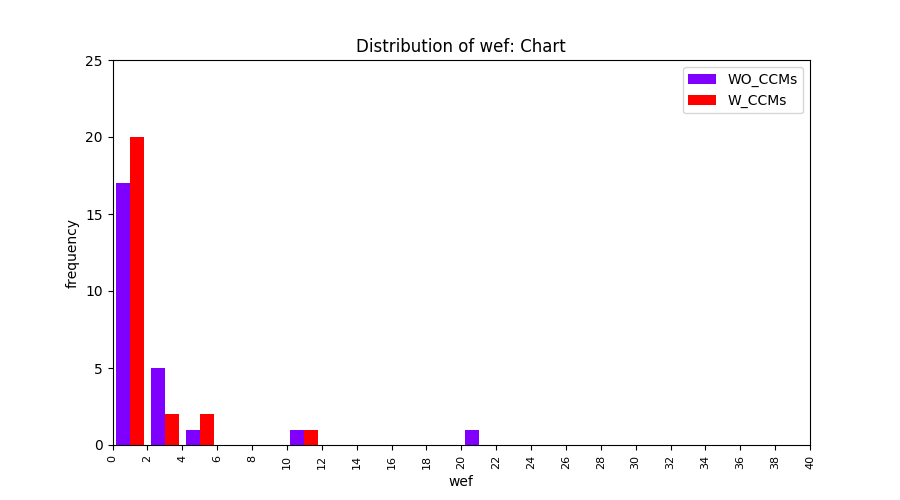
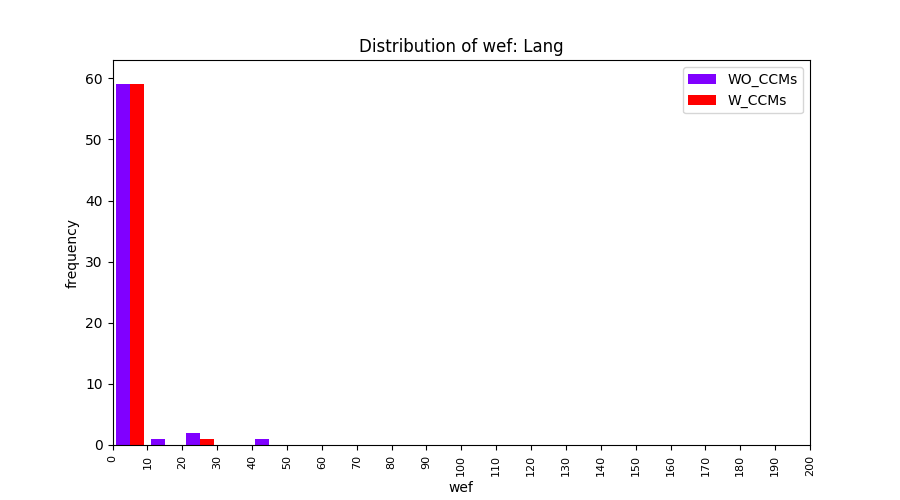
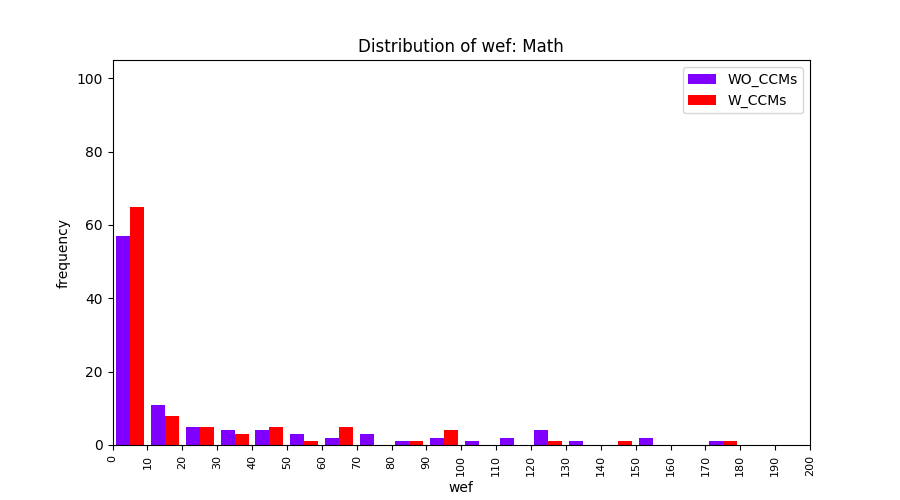
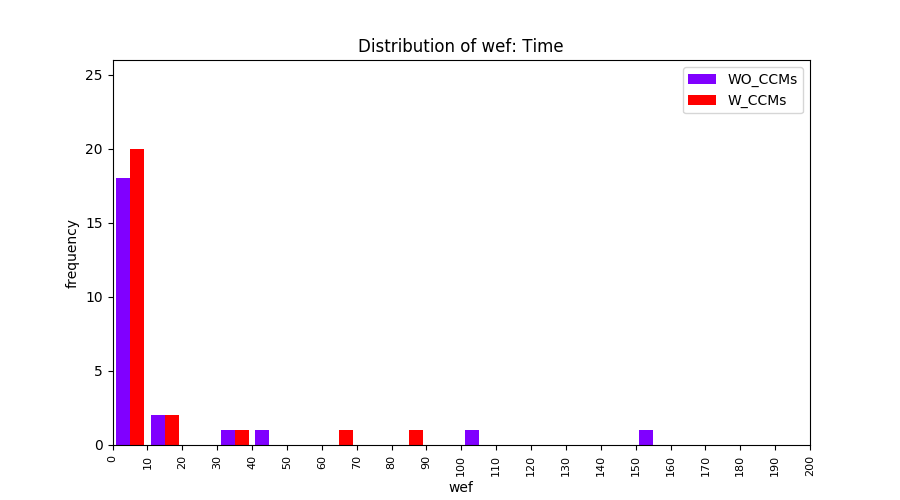
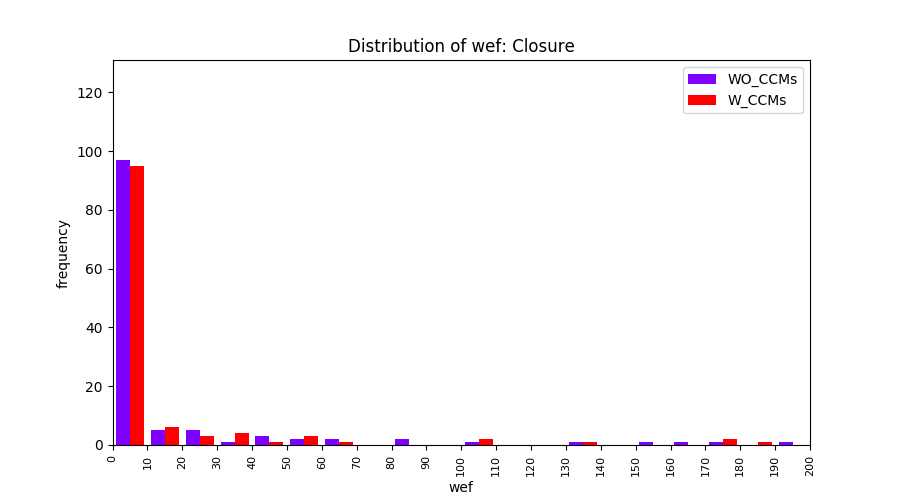
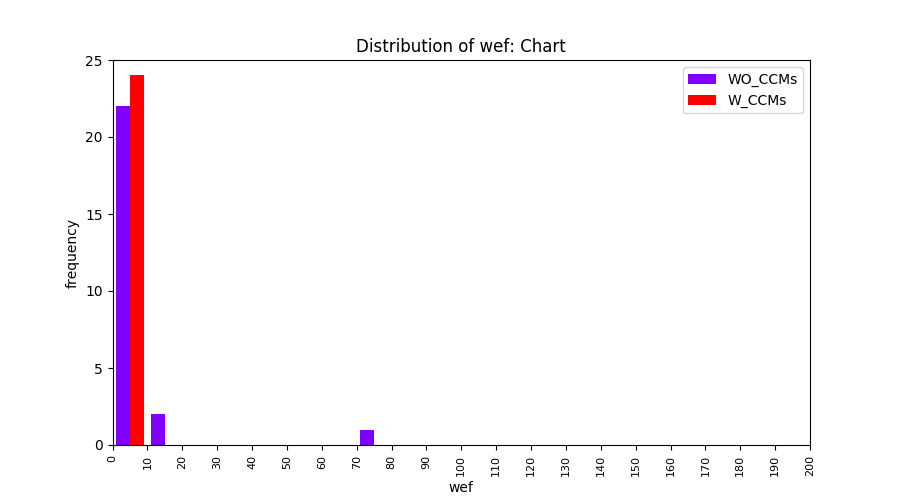
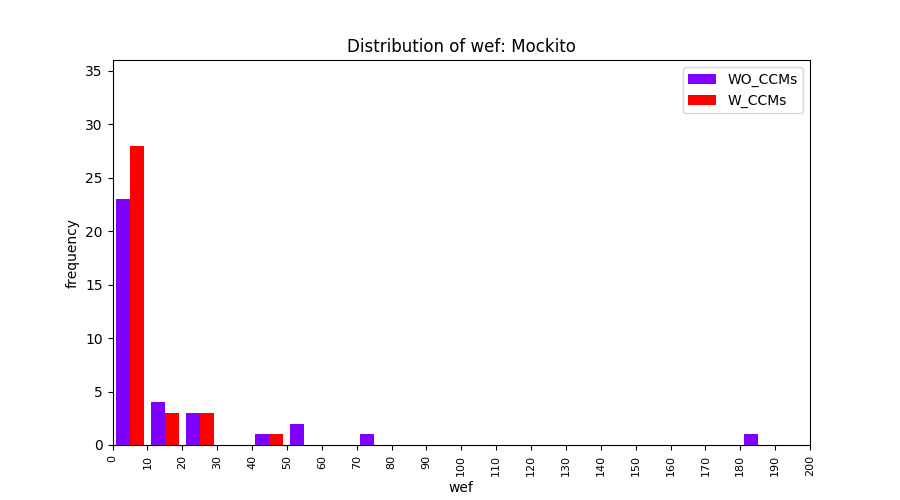
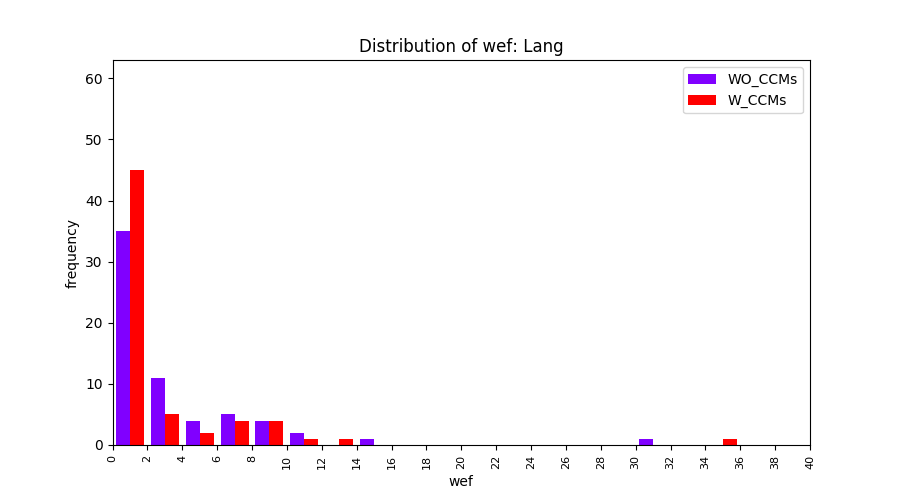
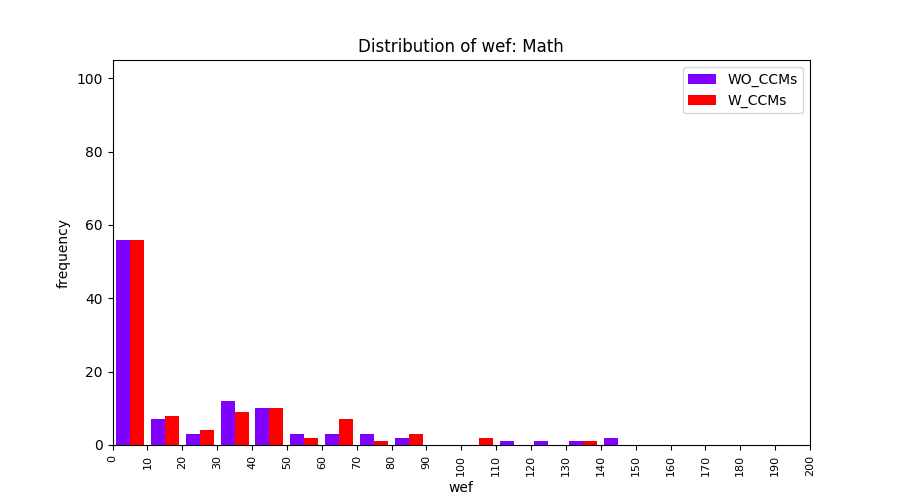
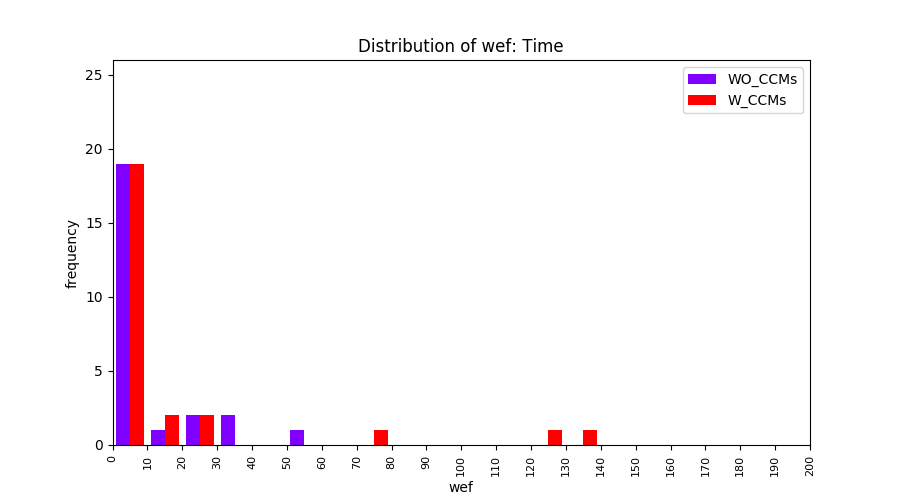
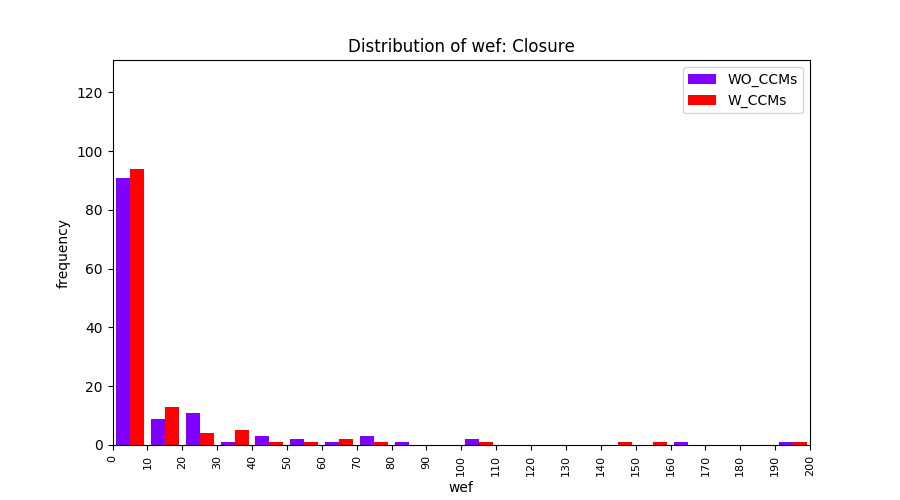
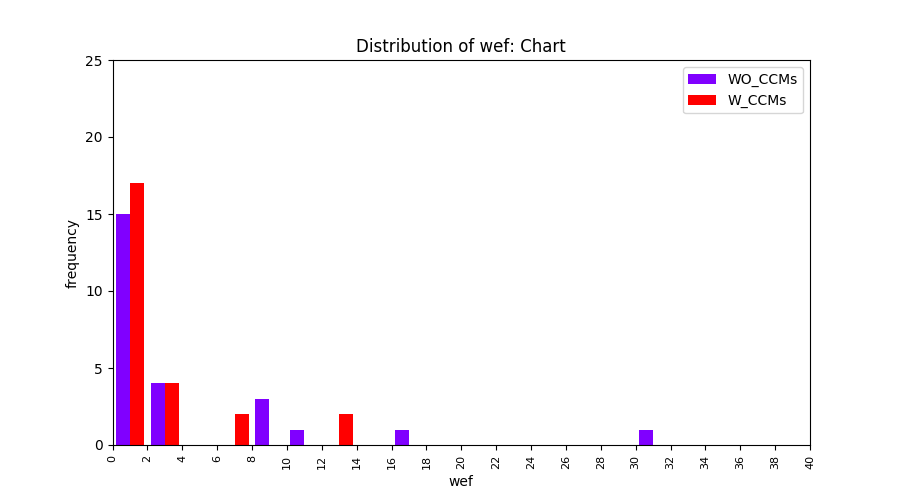
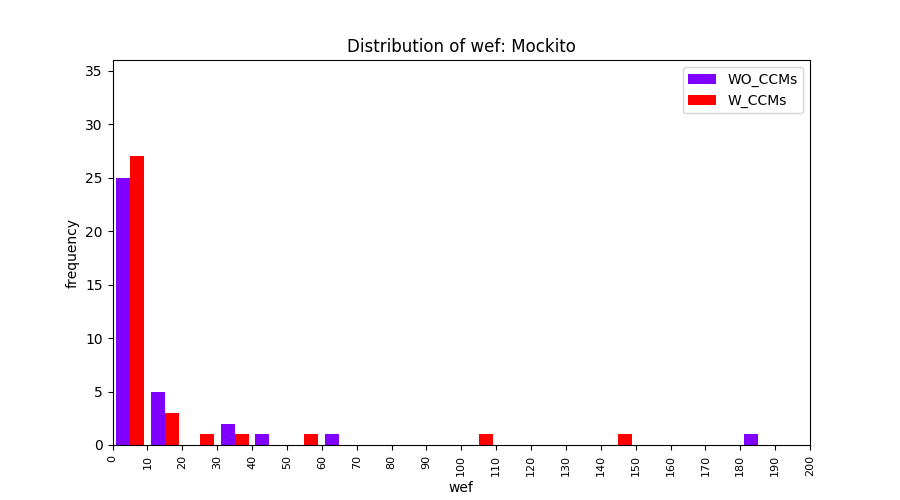
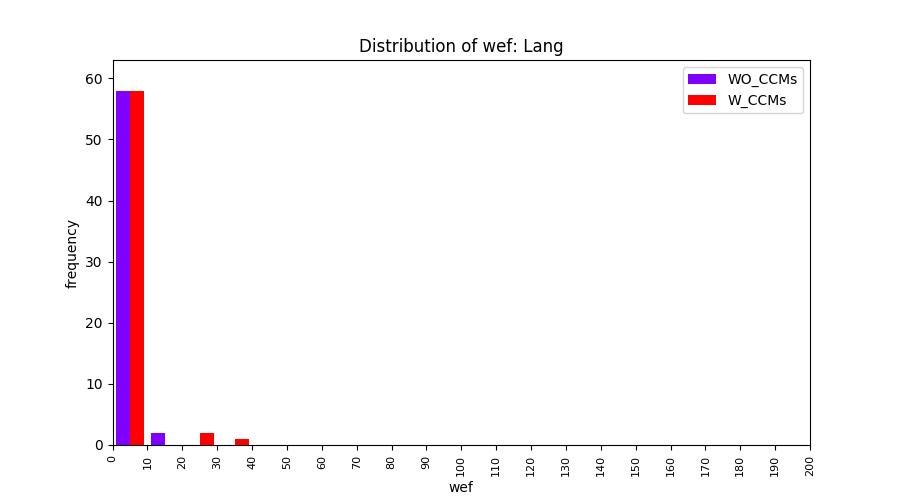
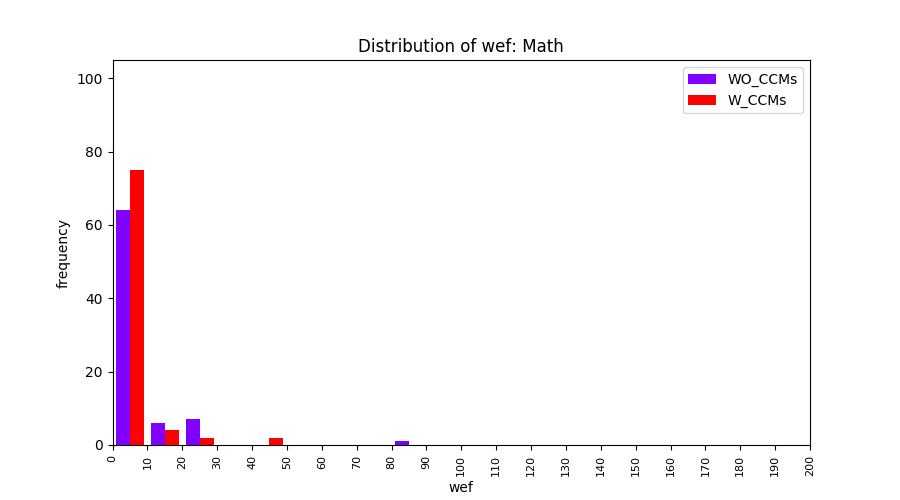
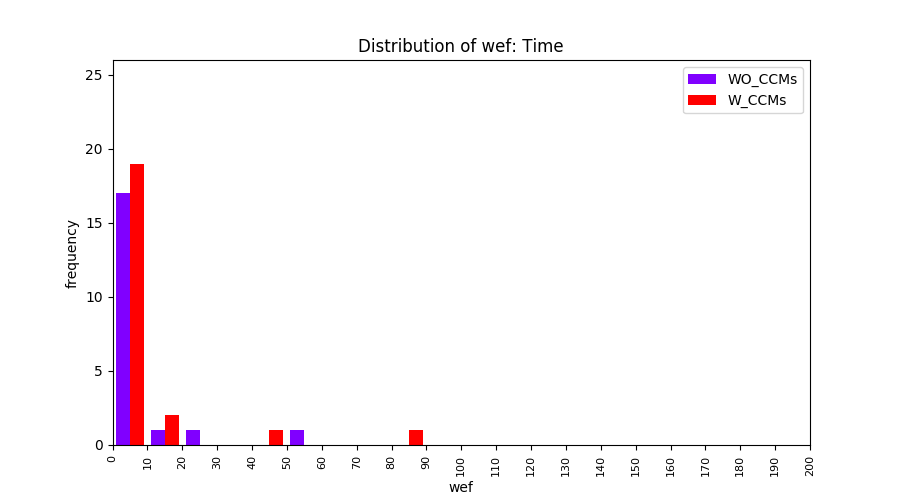
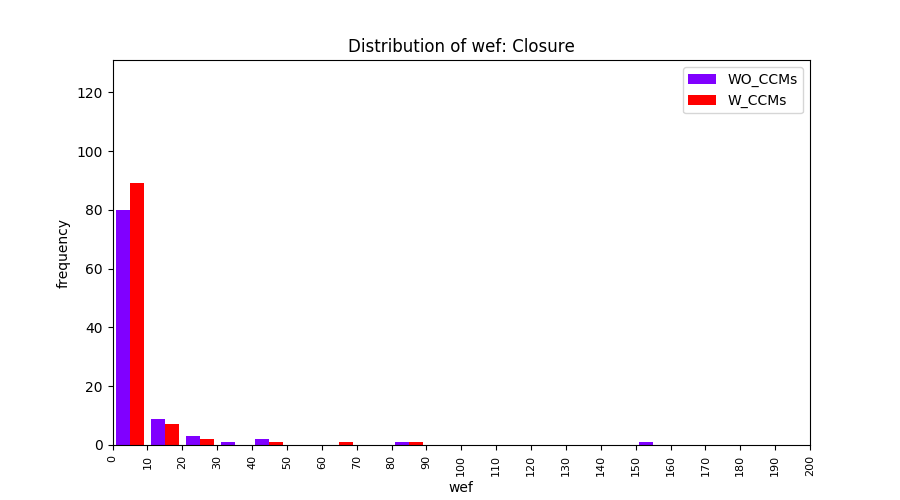
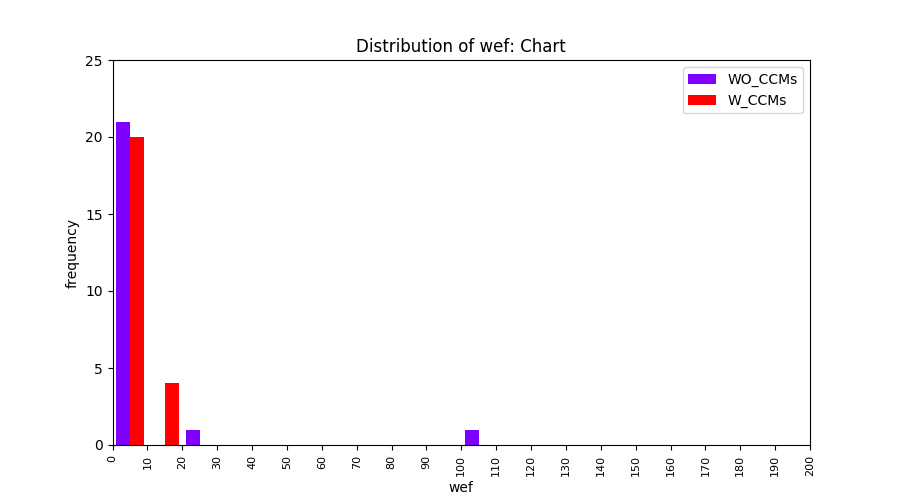
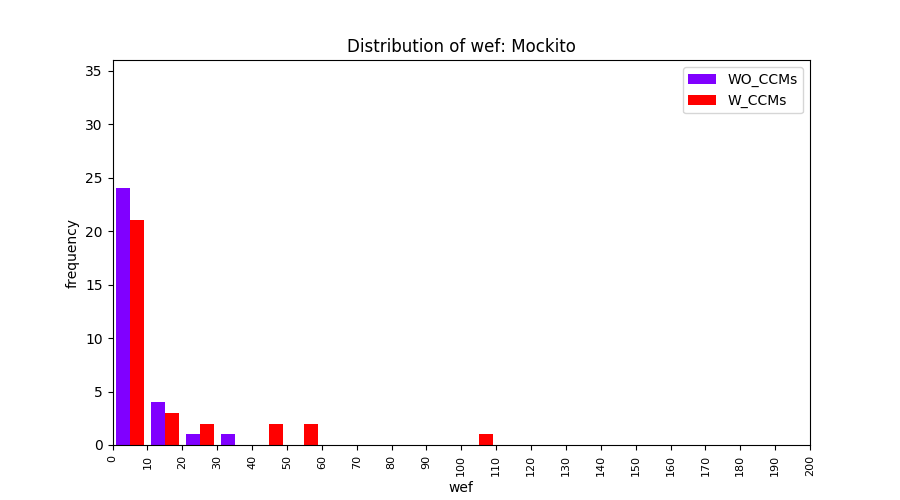
Main idea of FLUCCS, our new fault localization tool, is using code and change metrics, which have been widely used in defect prediction. Two types of histograms, one with code and change metrics and one without them, are shown in below to clarify promising improvement of exploiting code and change metrics in fault localization using FLUCCS with GP as the learning mechanism.
| Lang |
| Math |
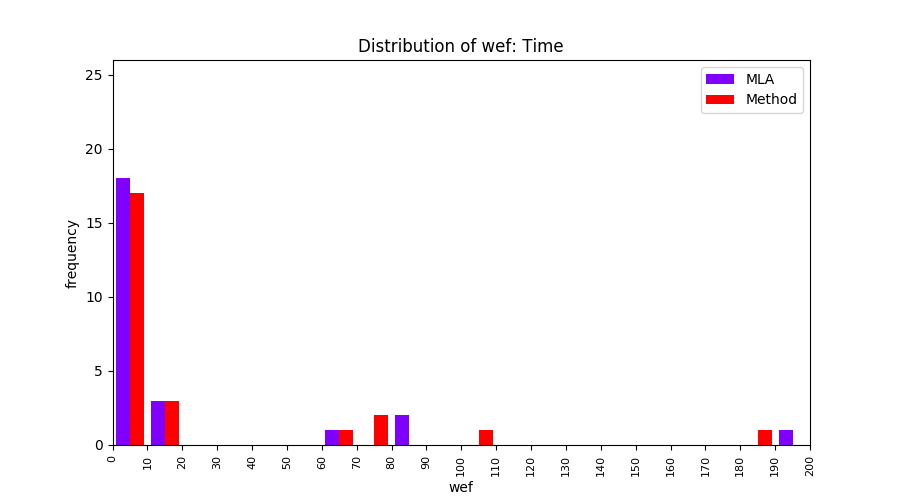
| Time |
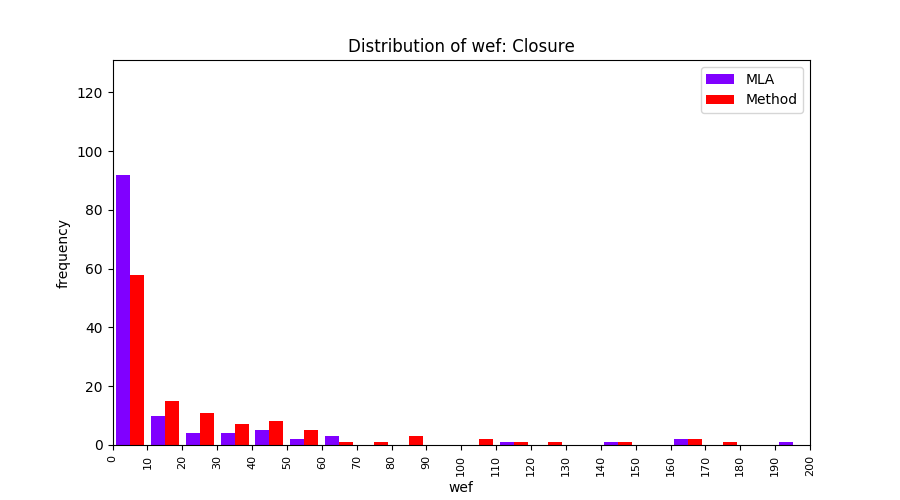
| Closure |
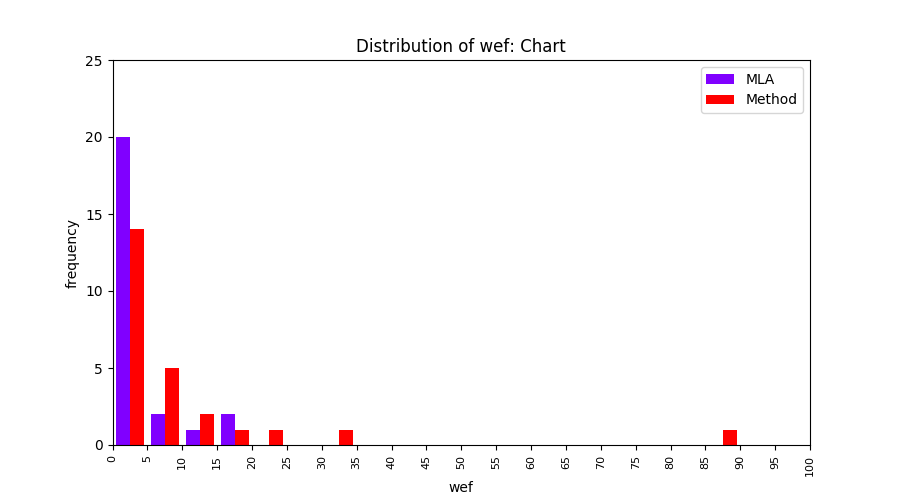
| Chart |
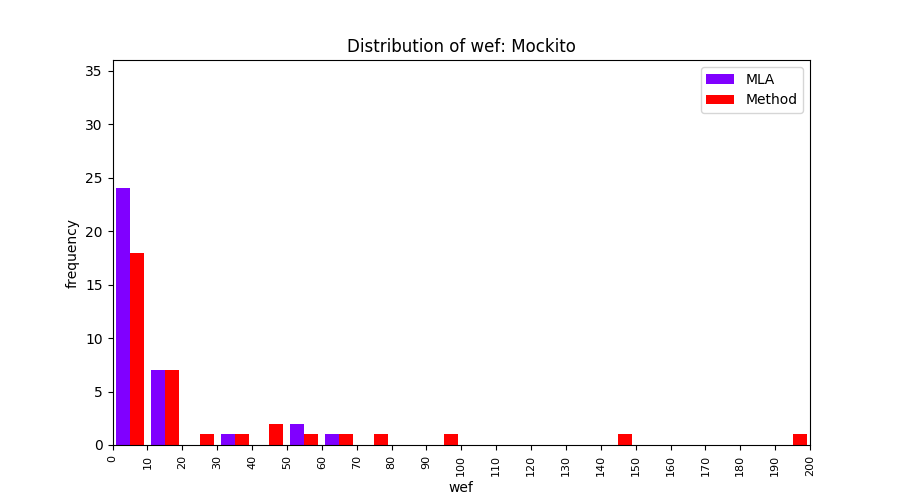
| Mockito |
To further clarify the effect of employing code and change metrics in fault localization, we compare the results of three other learning mechanisms (Gaussian Process, Linear rankingSVM, Random Forest) with and without code and change metrics. From these comparisions, we insist that the benefit of using code and change metrics is not limited to GP.
| Gaussian Process |
| Linear ranking SVM |
| Random Forest |
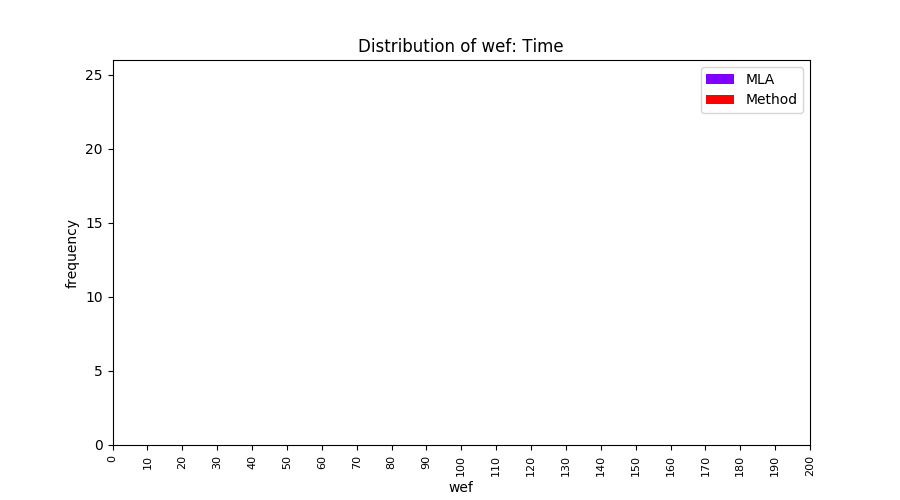
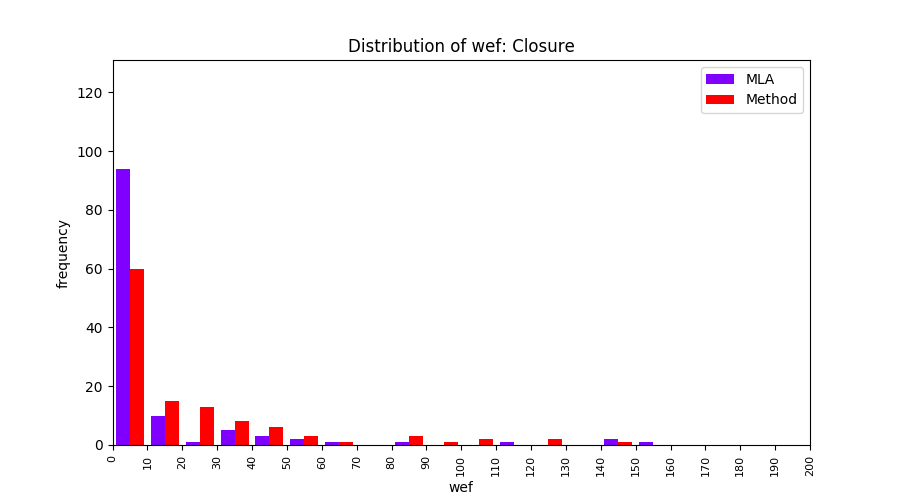
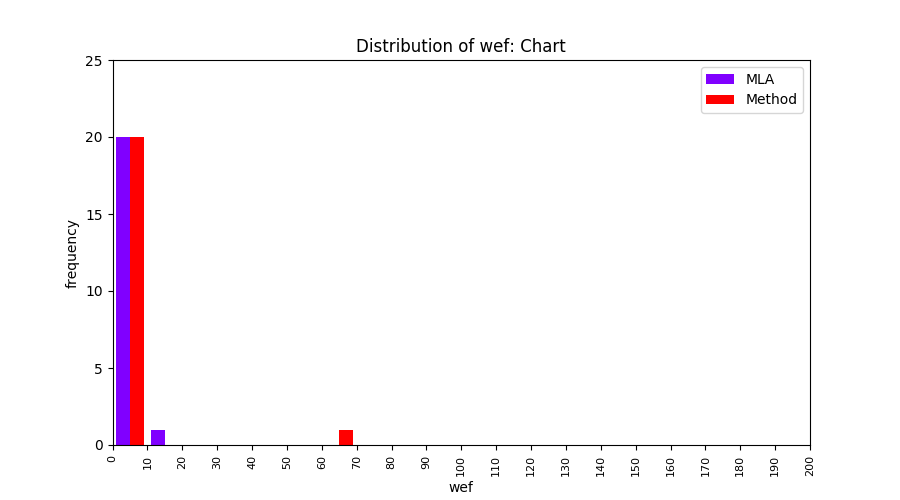
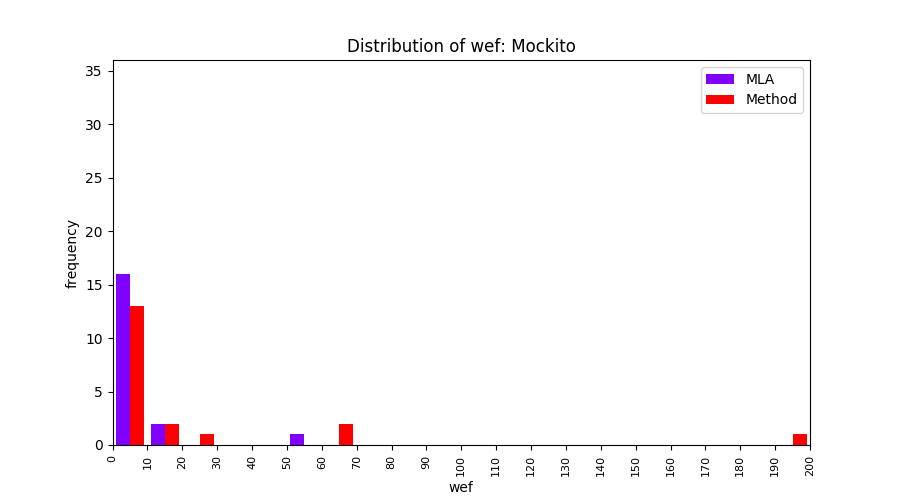
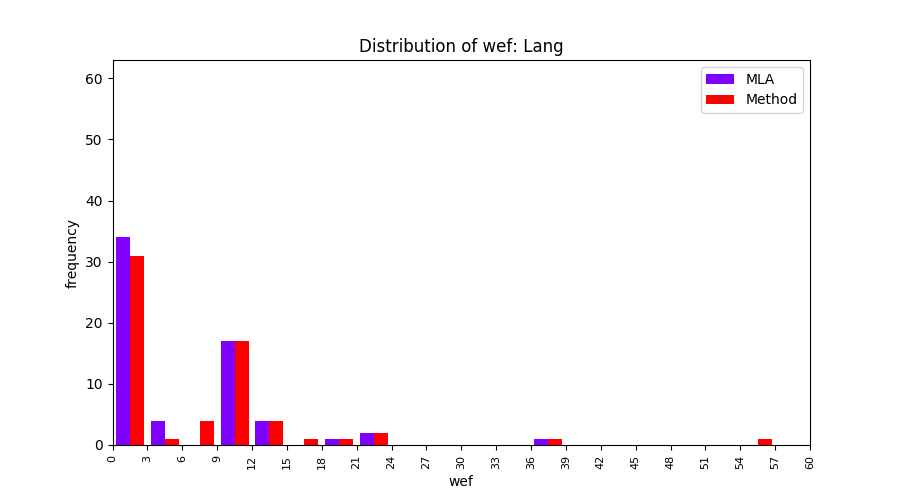
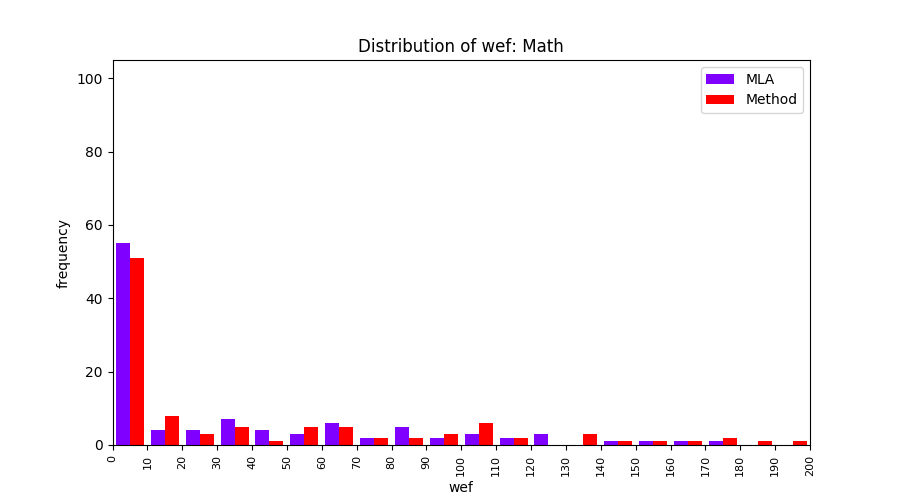
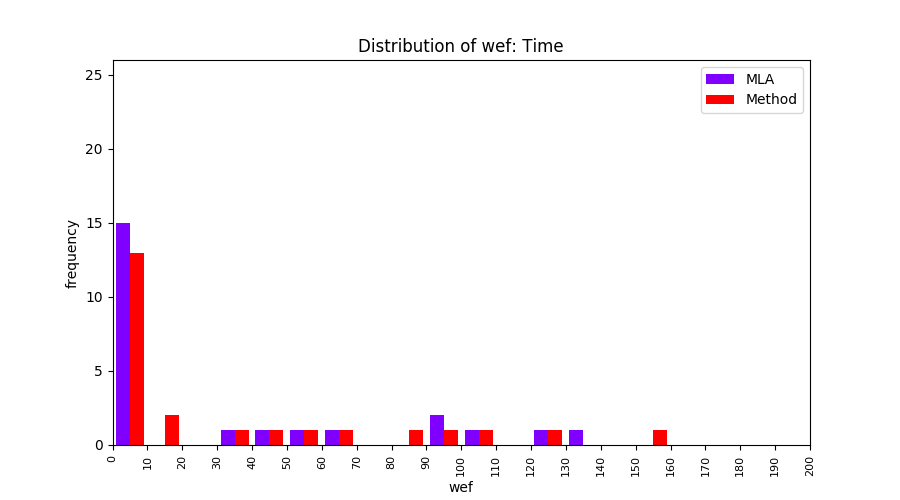
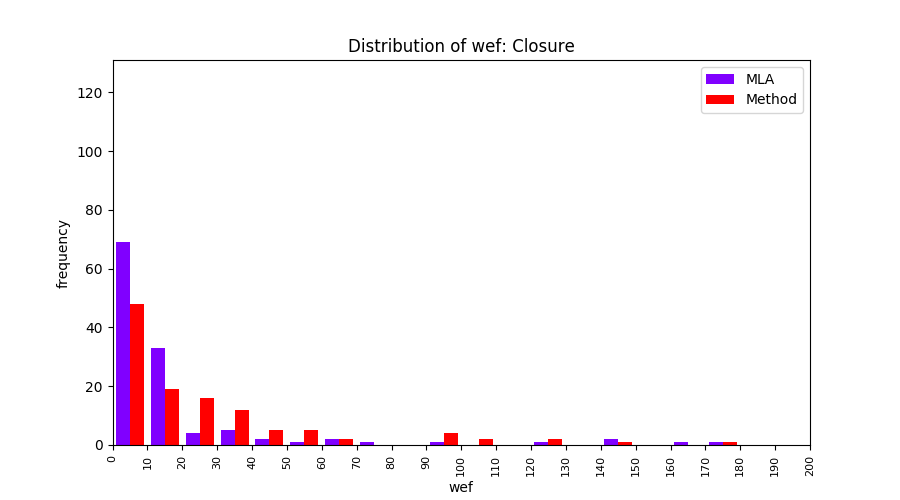
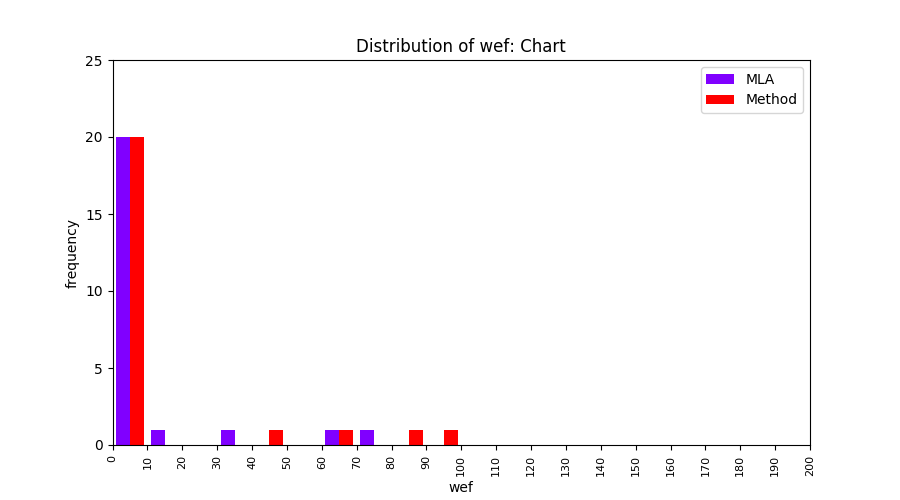
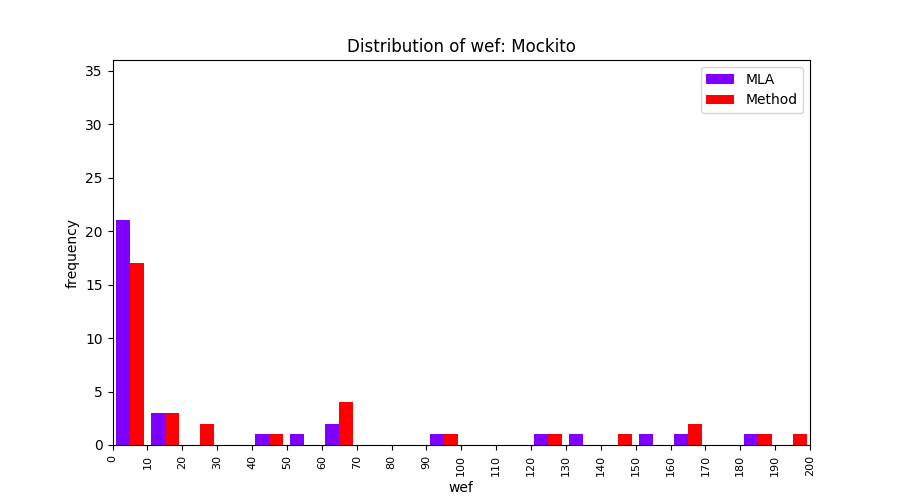
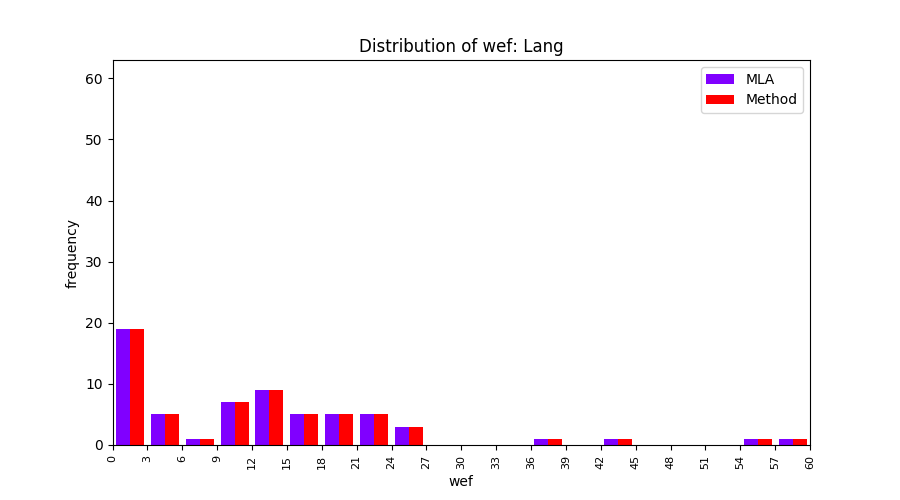
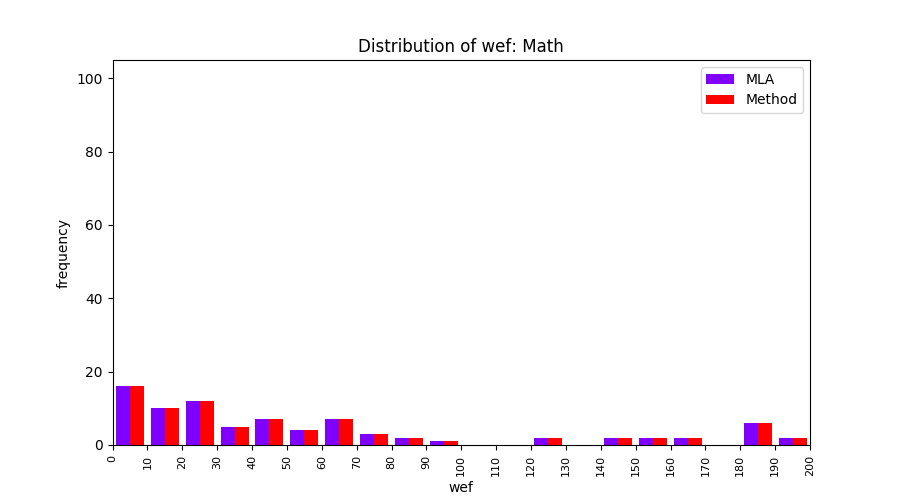
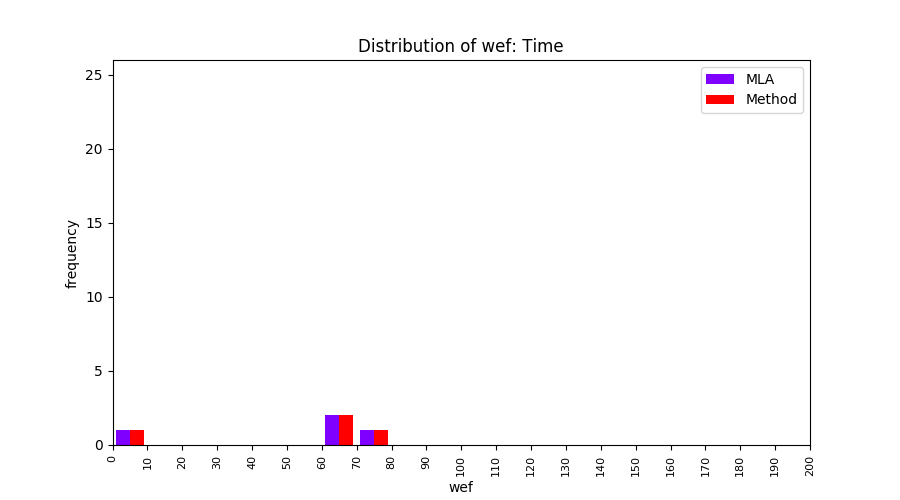
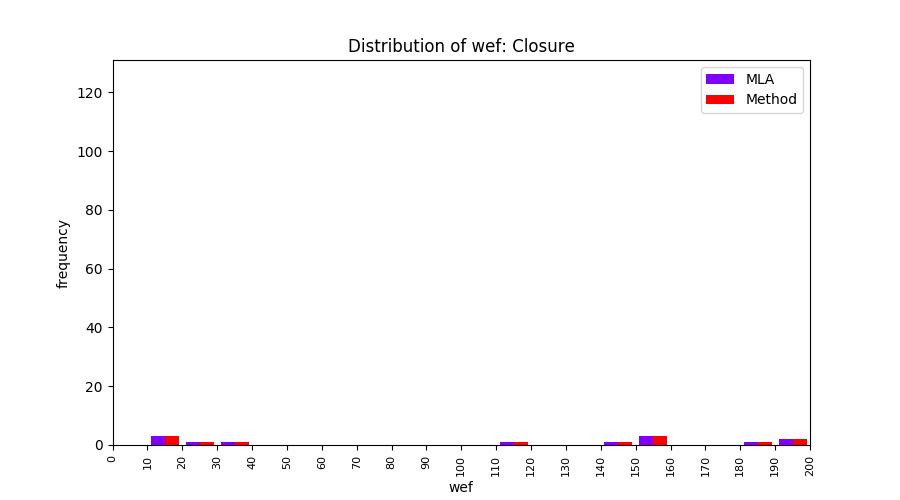
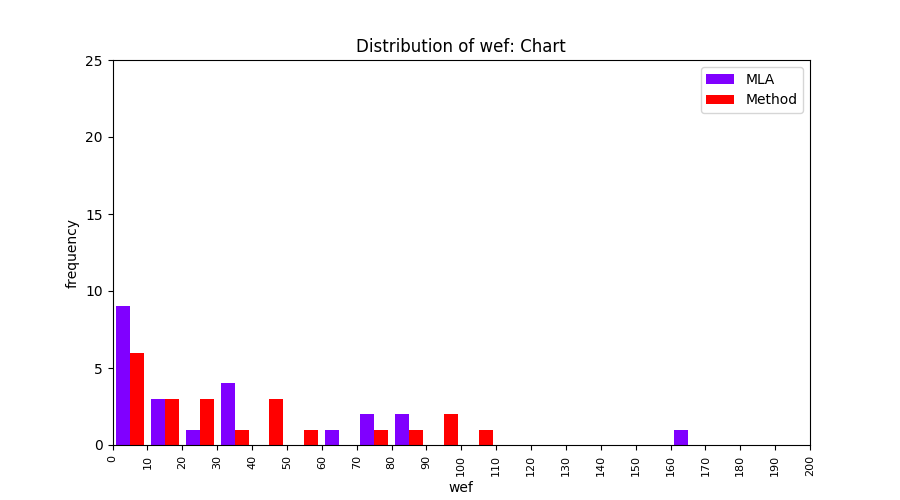
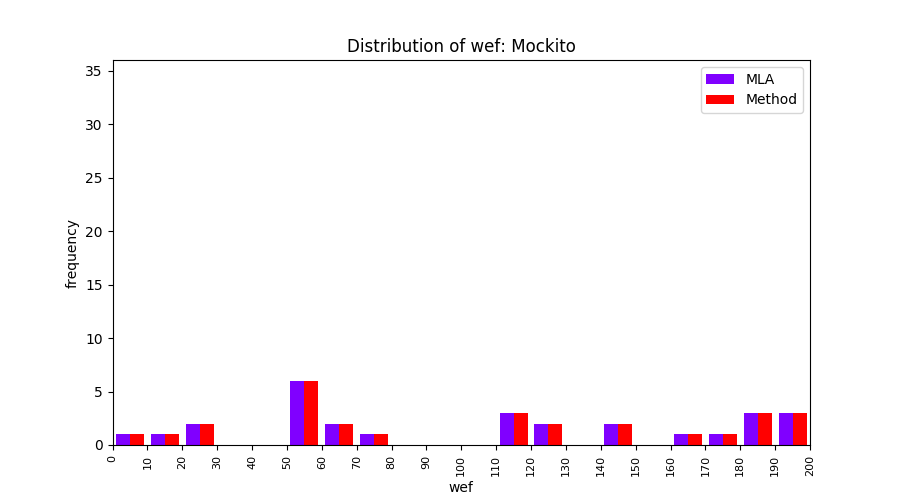
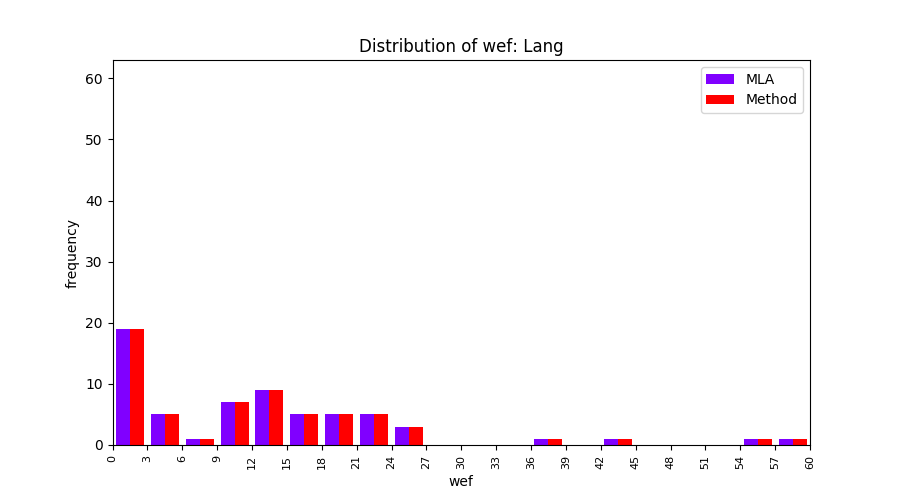
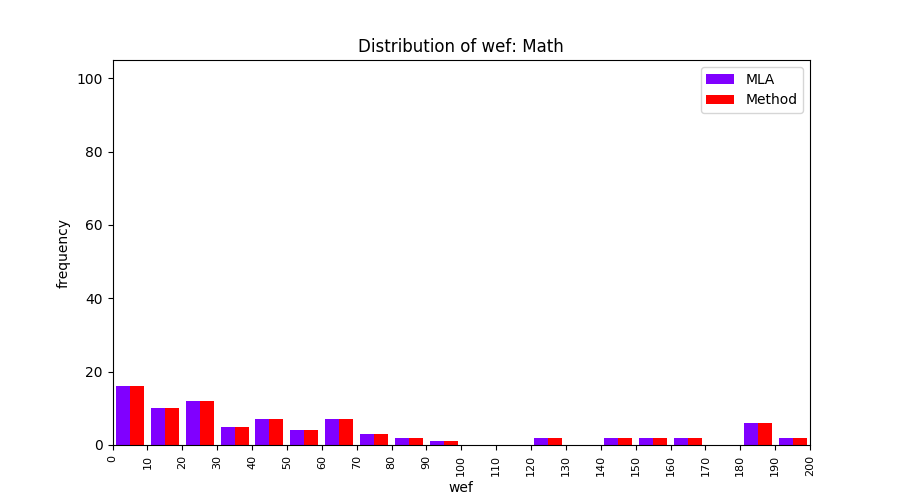
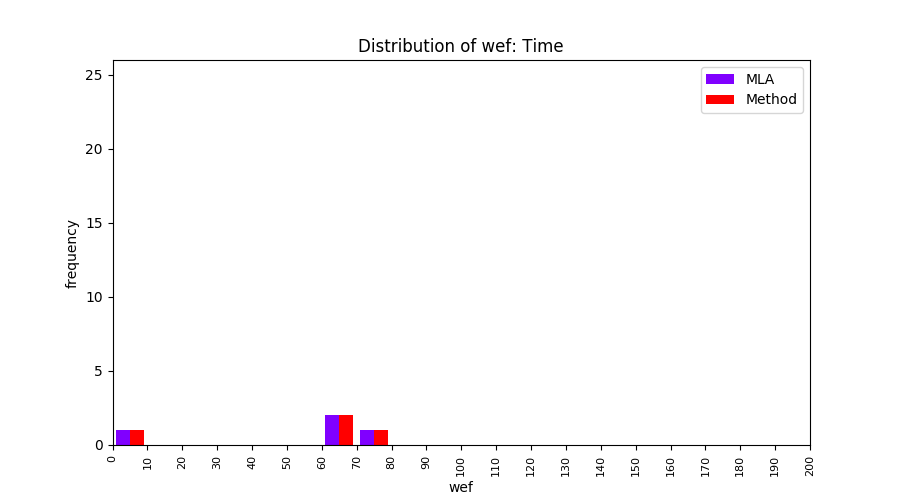
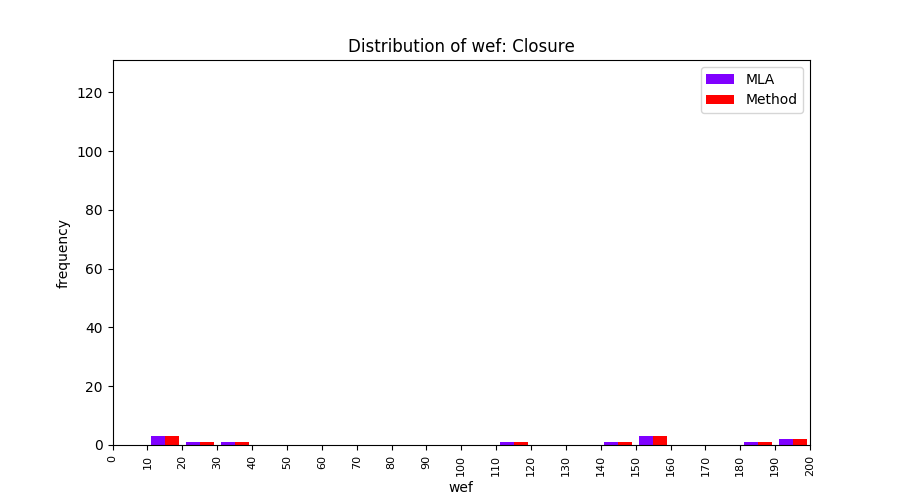
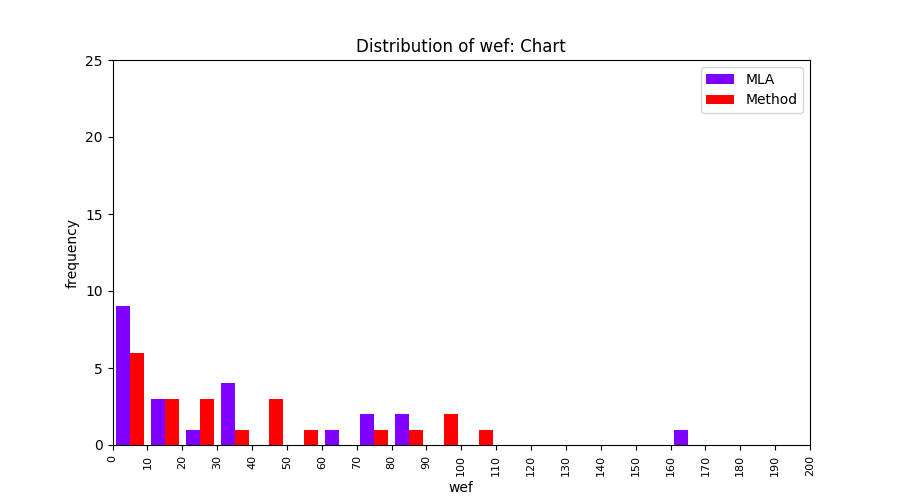
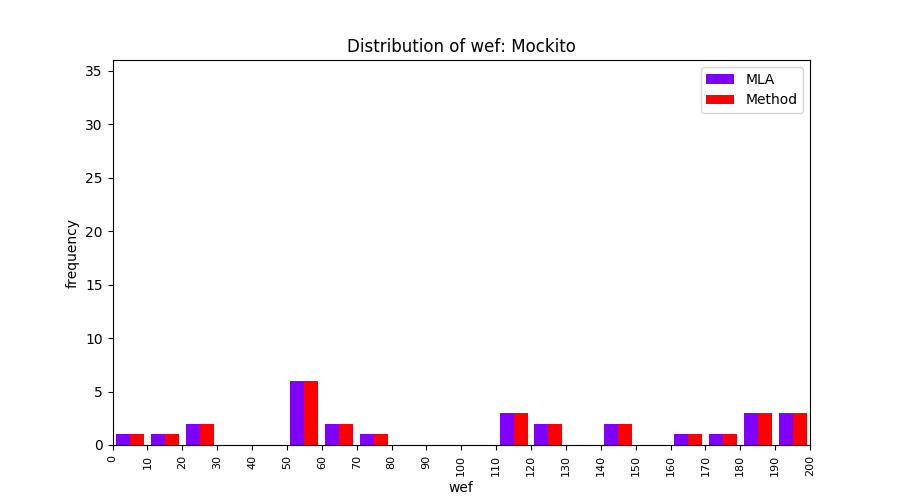
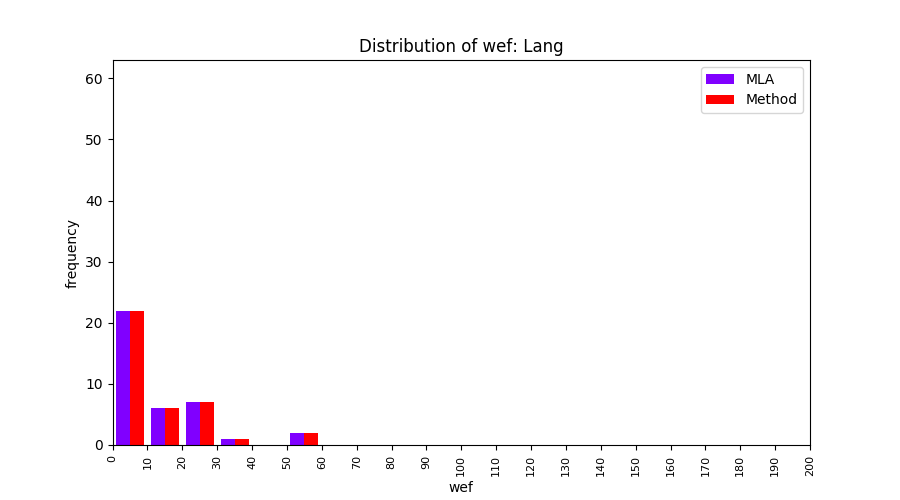
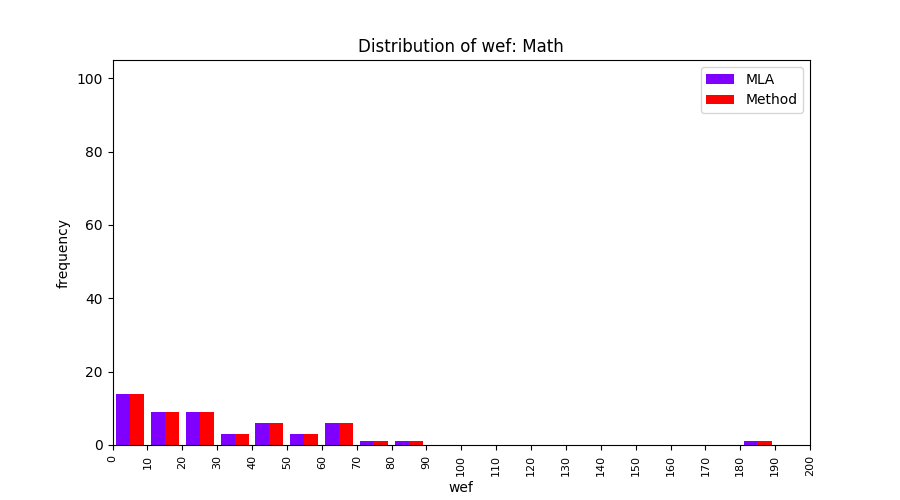
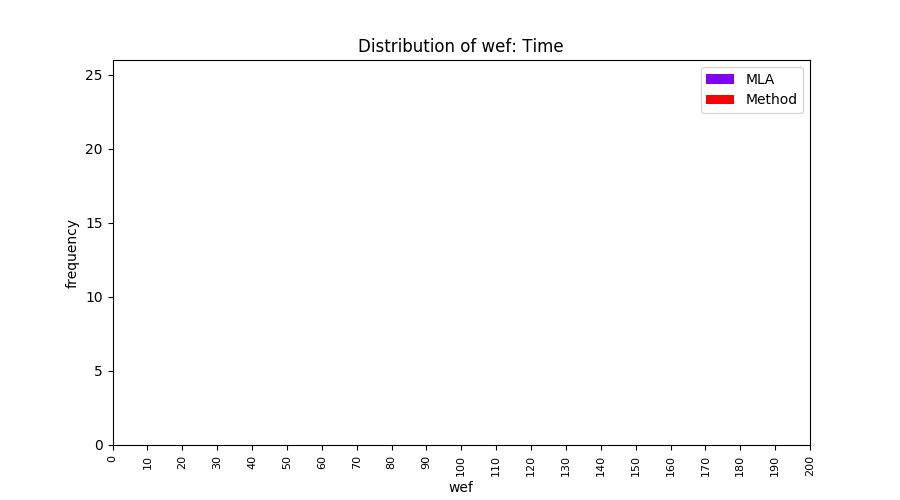
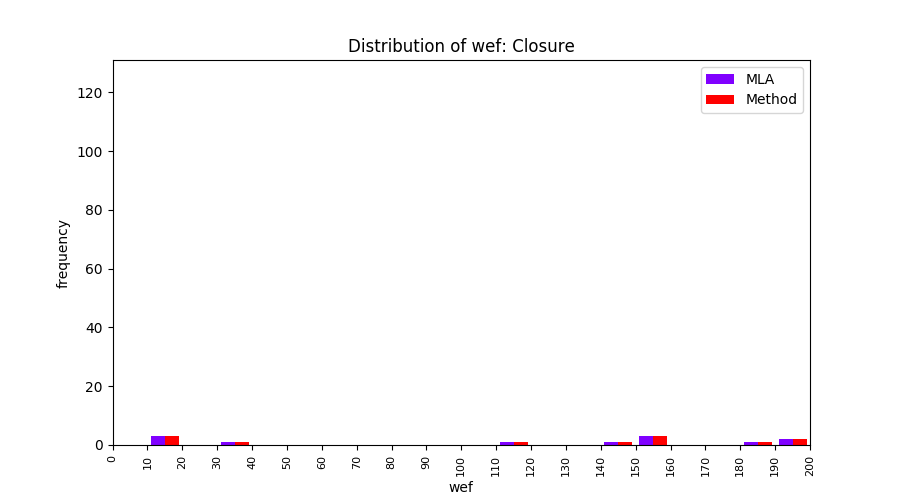
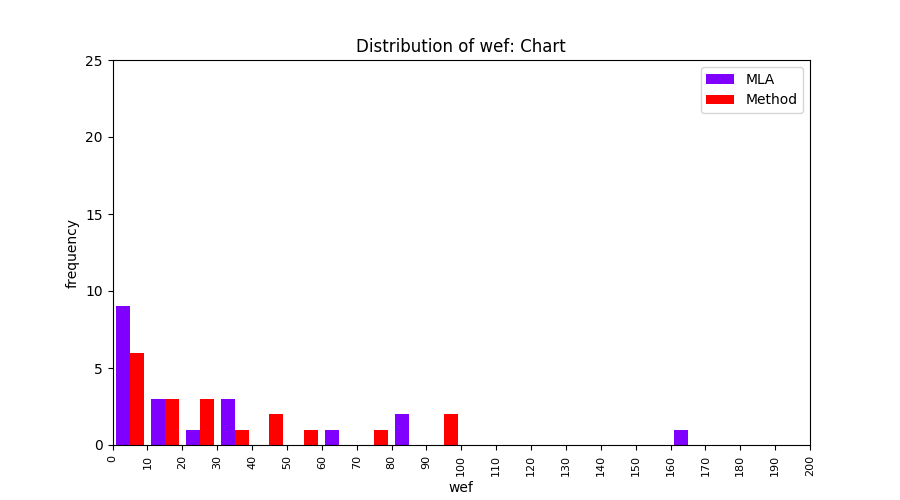
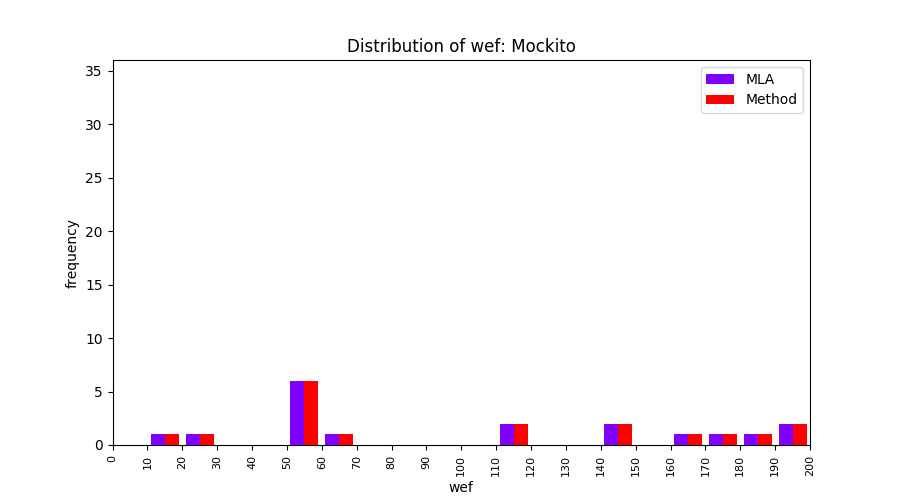
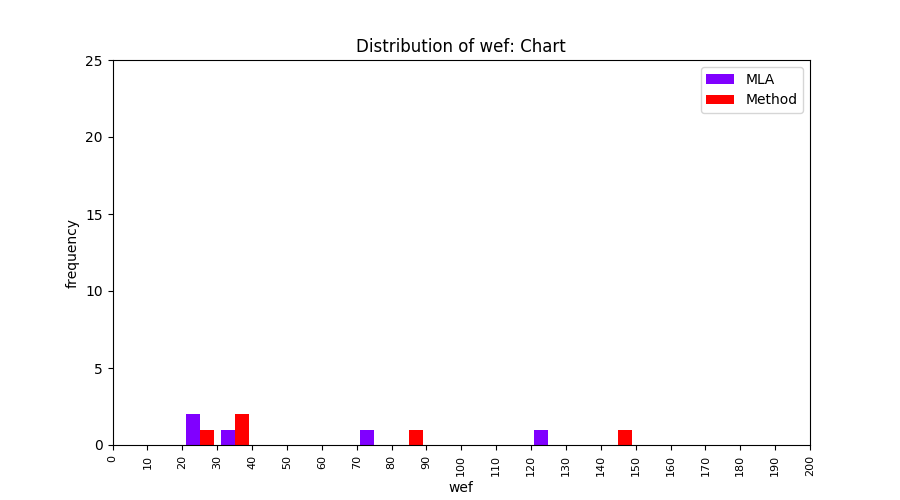
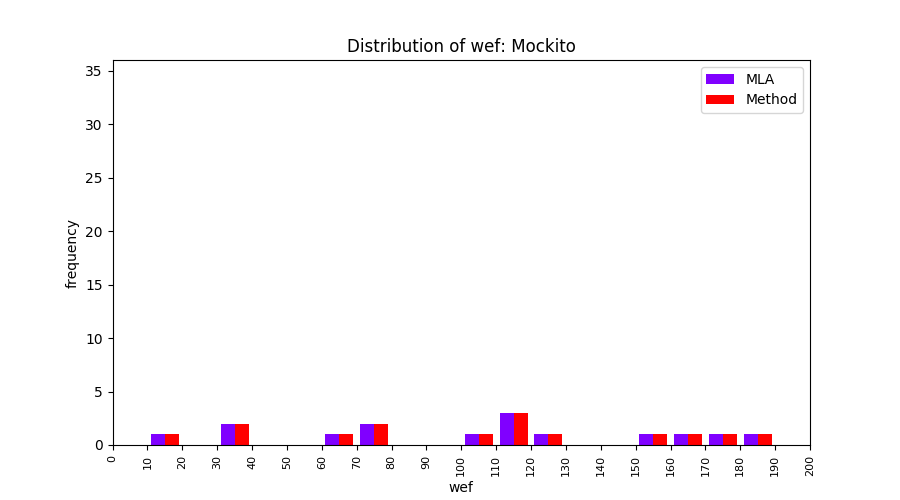
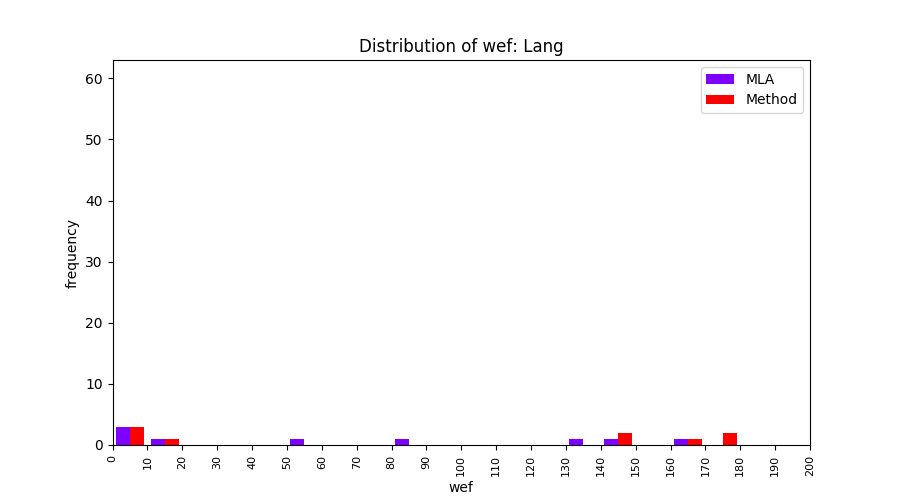
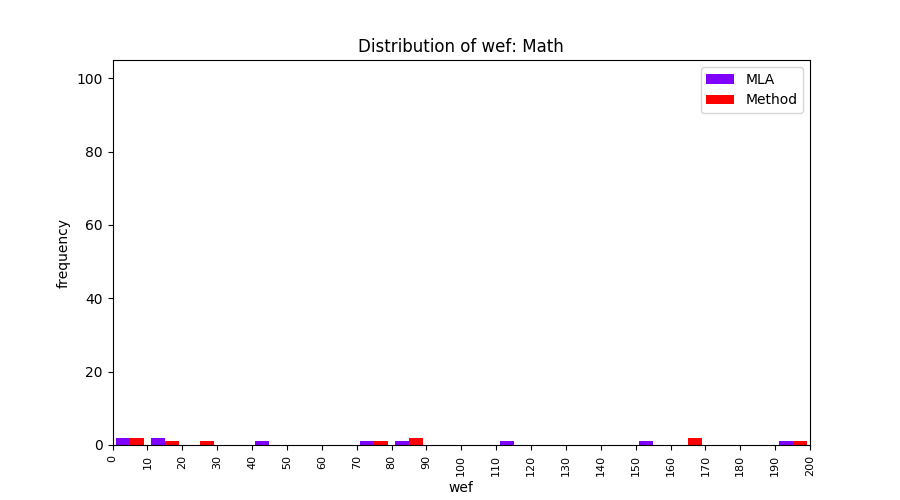
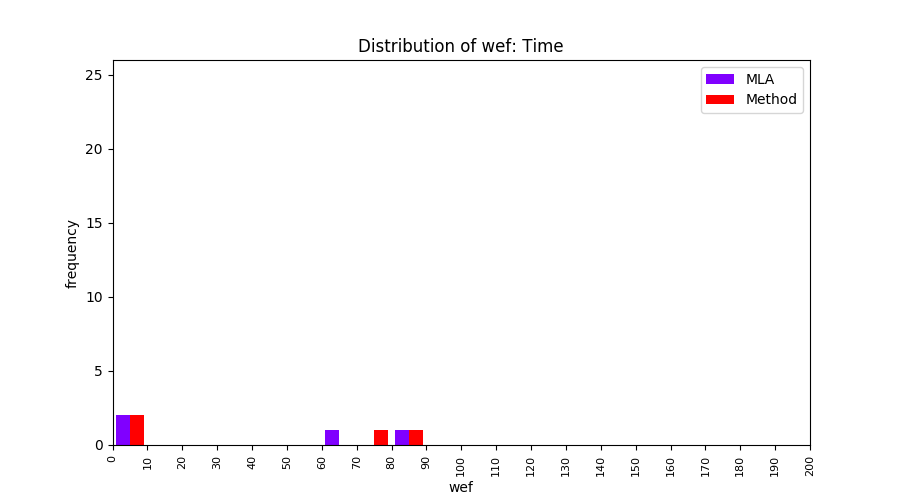
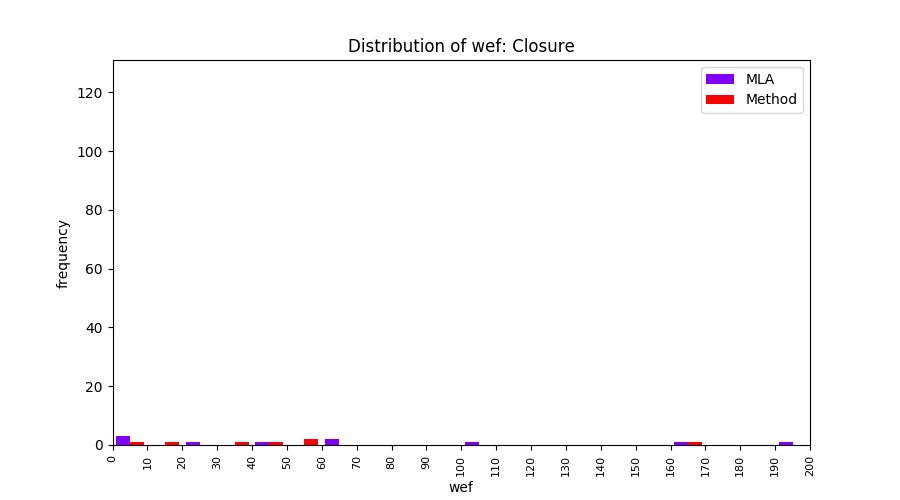
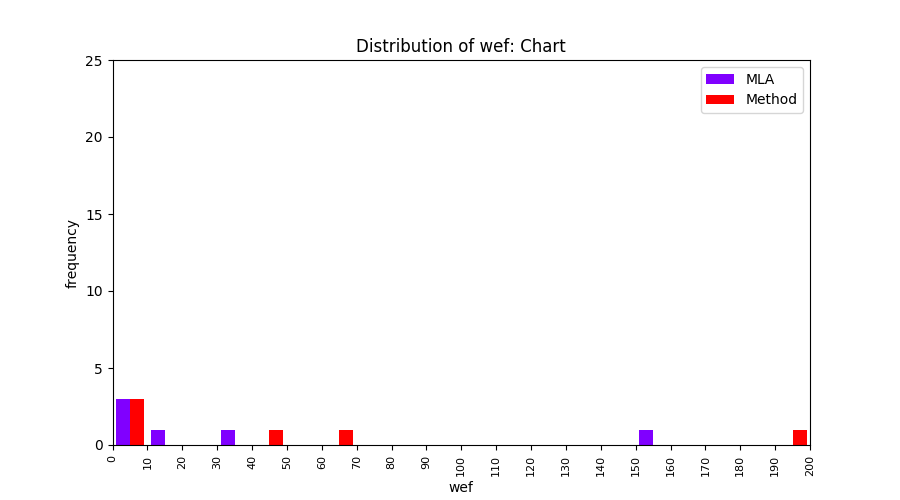
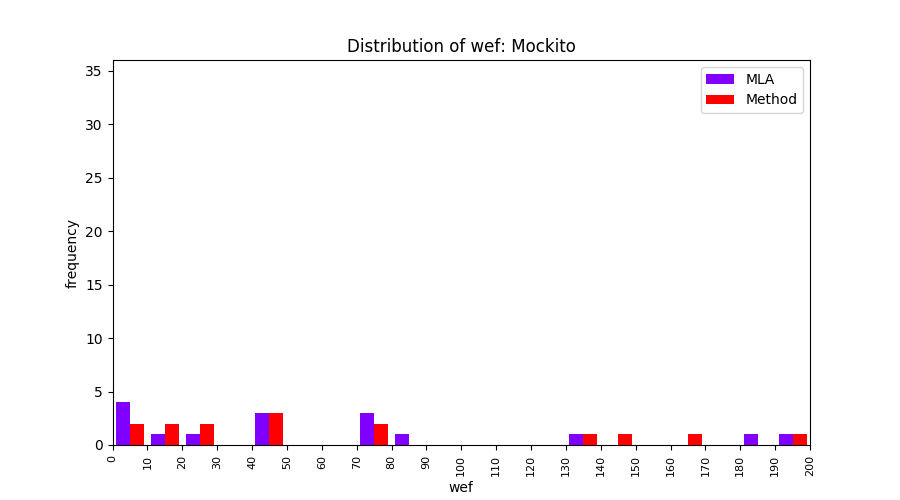
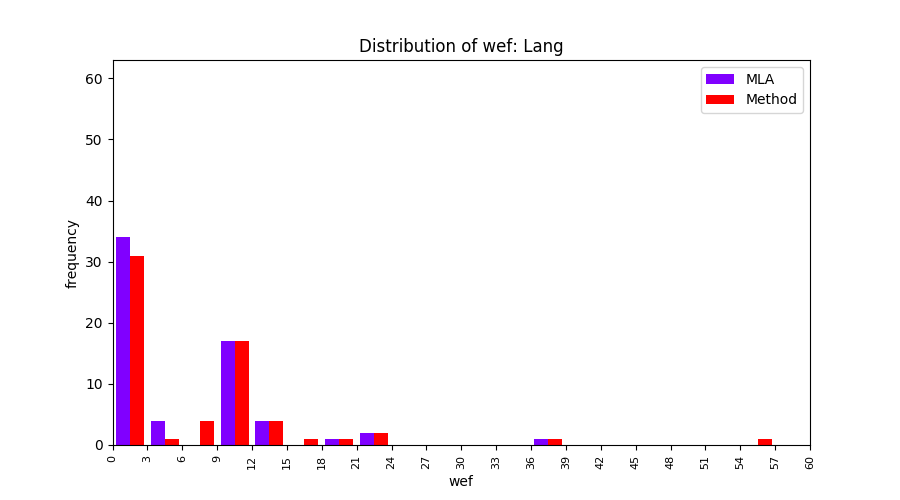
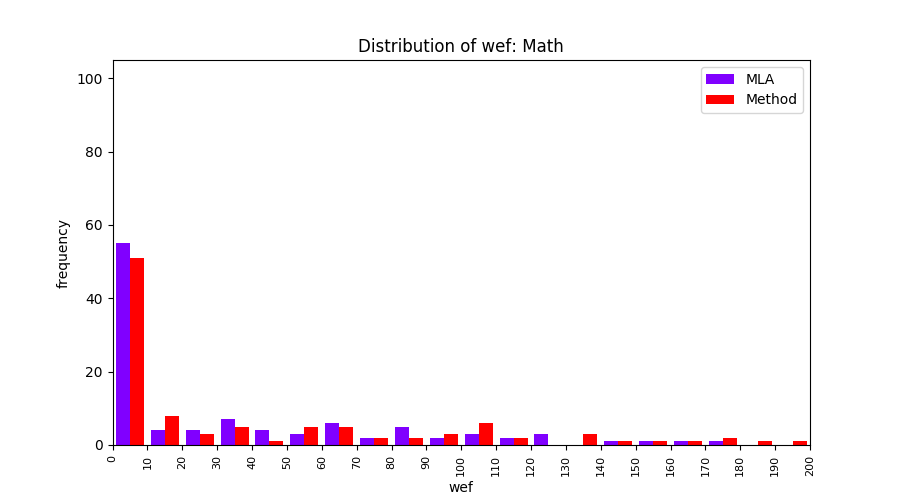
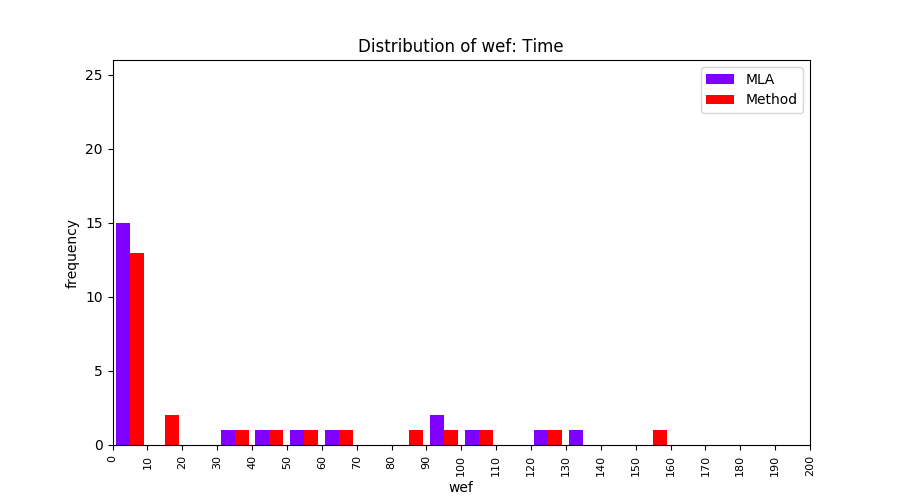
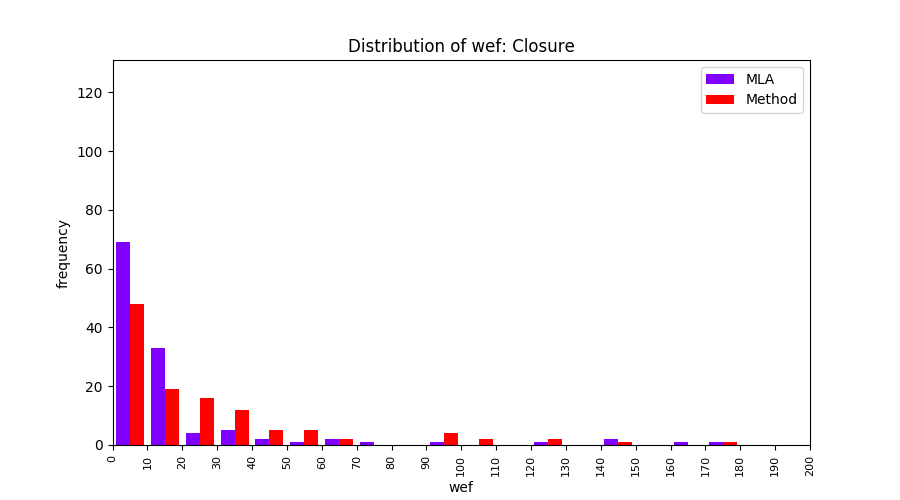
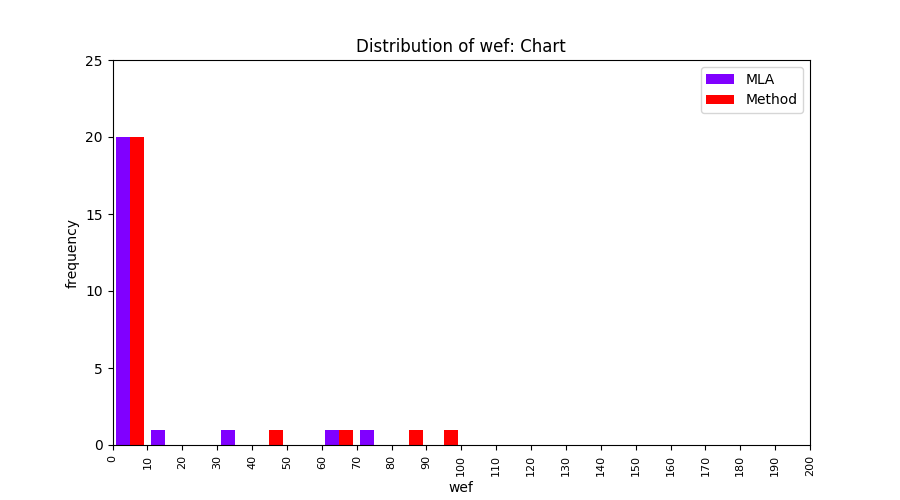
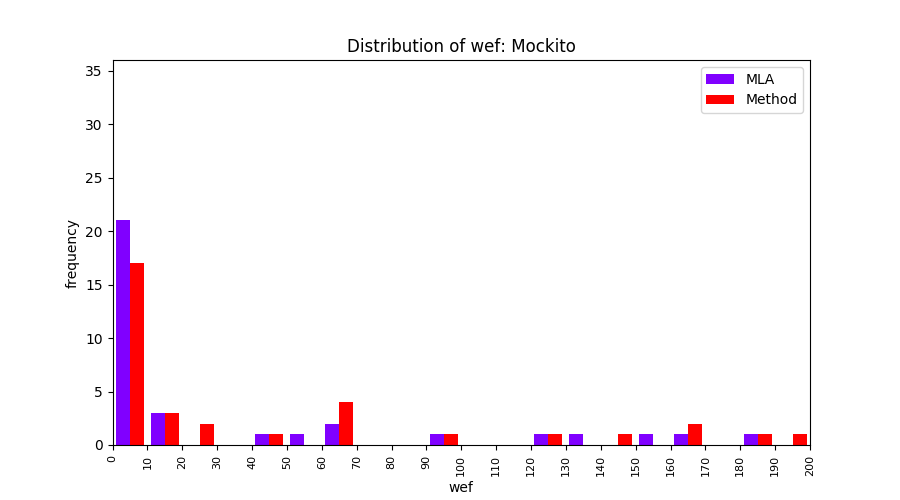
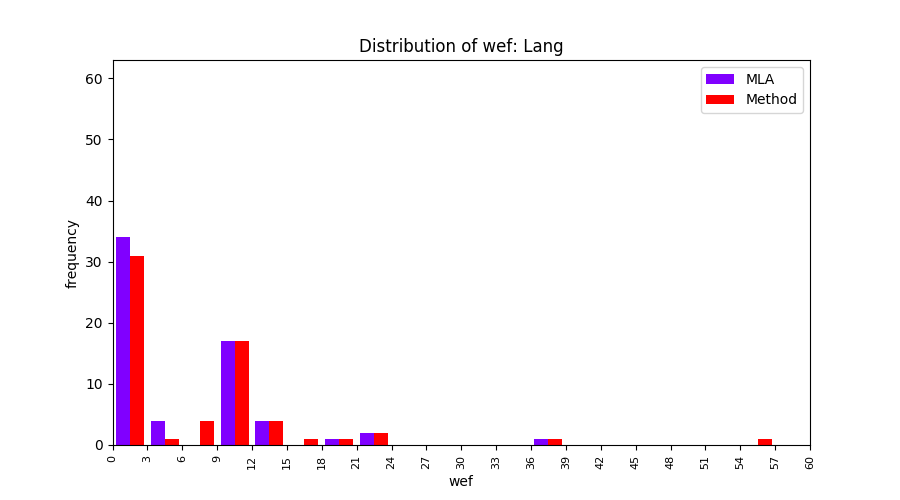
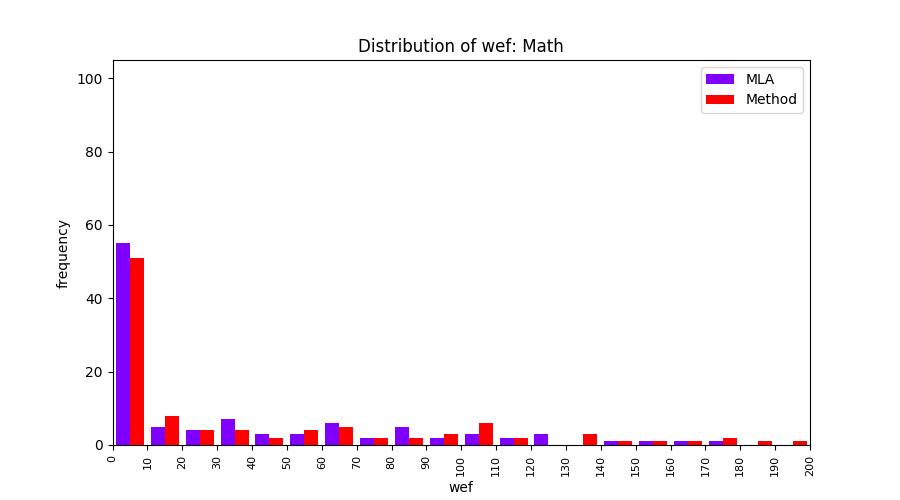
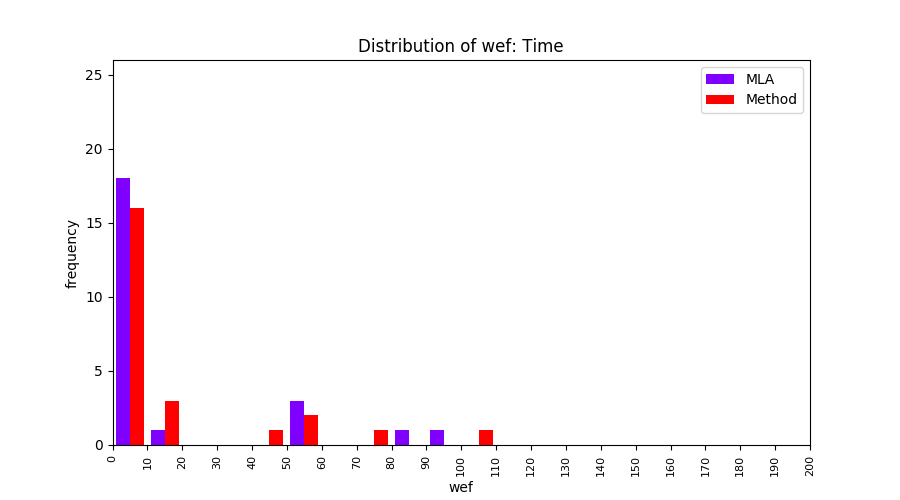
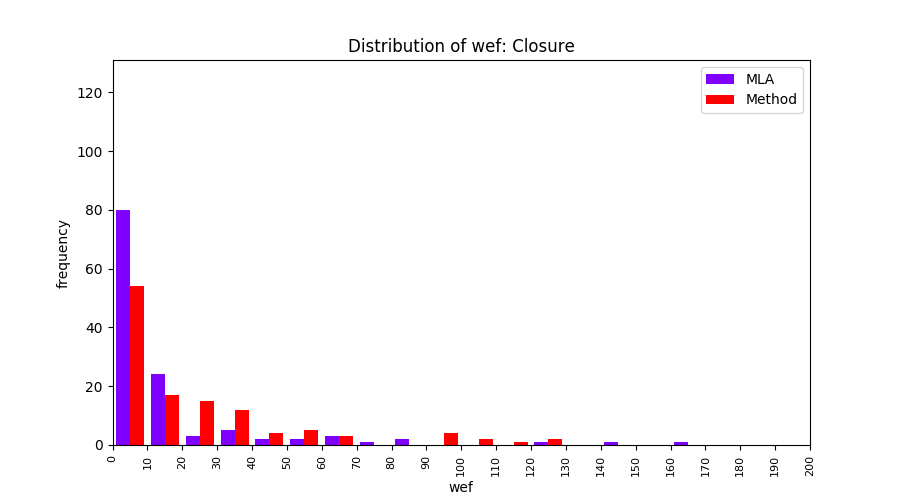
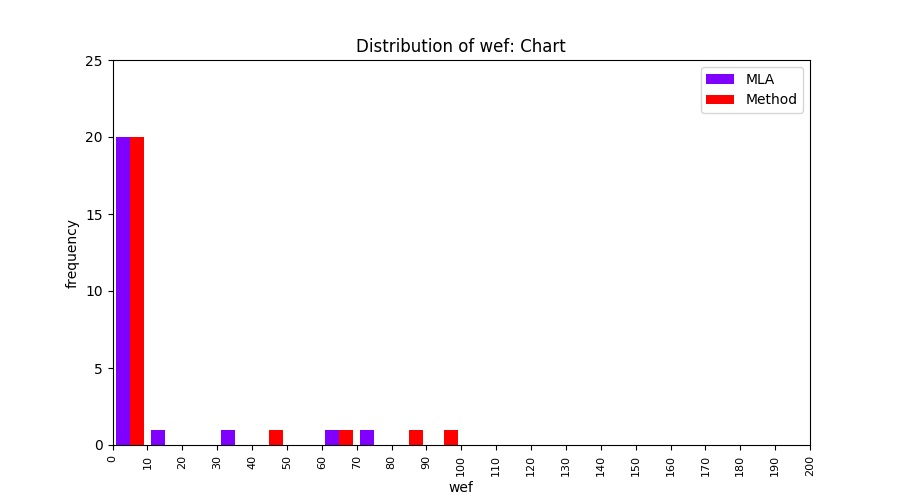
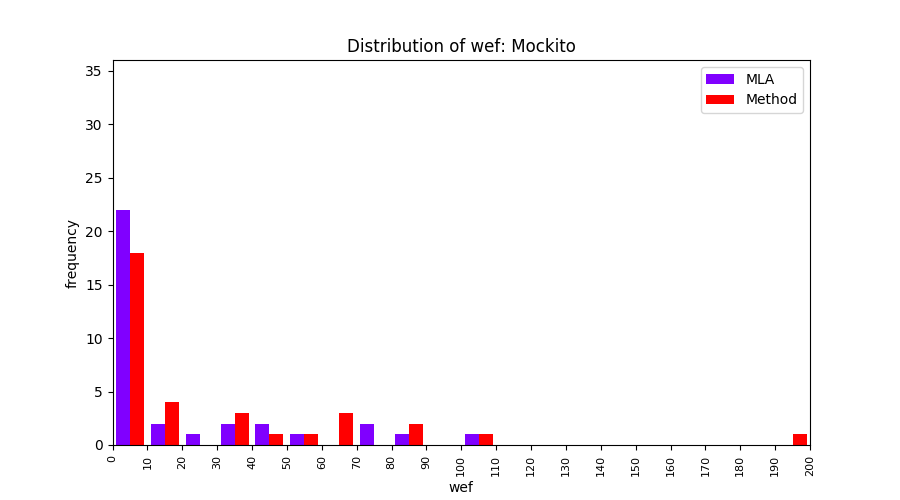
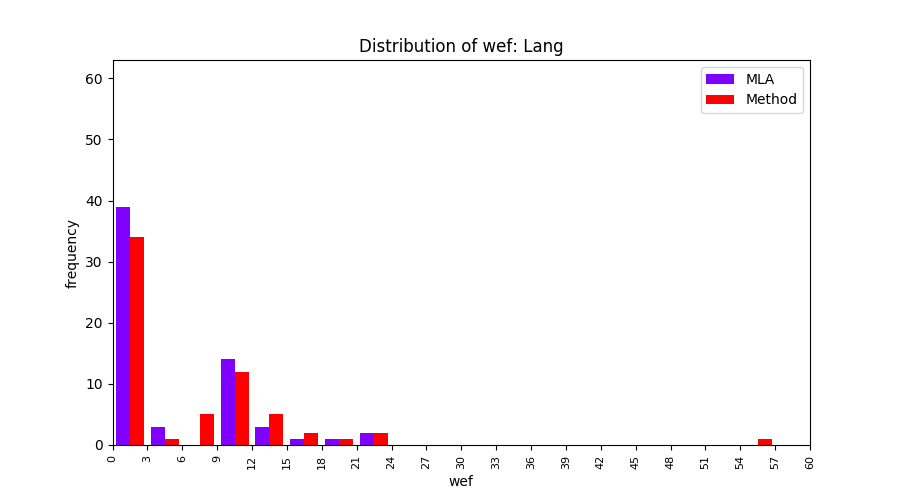
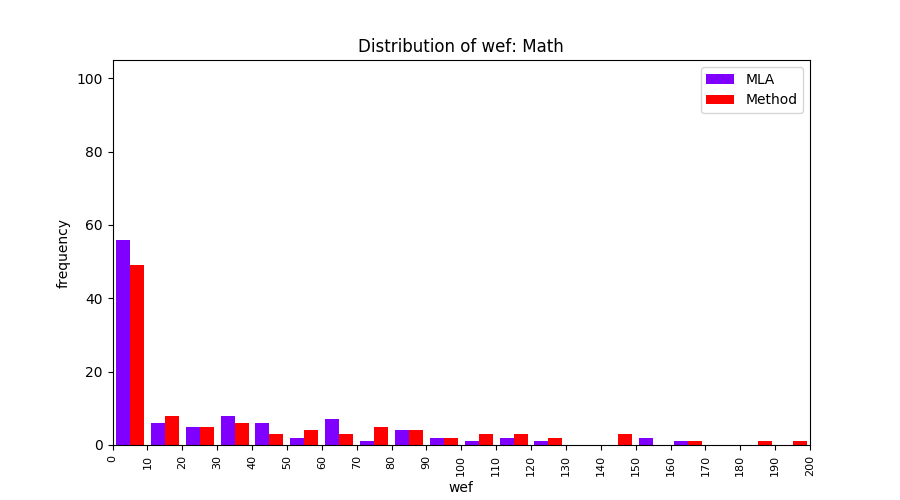
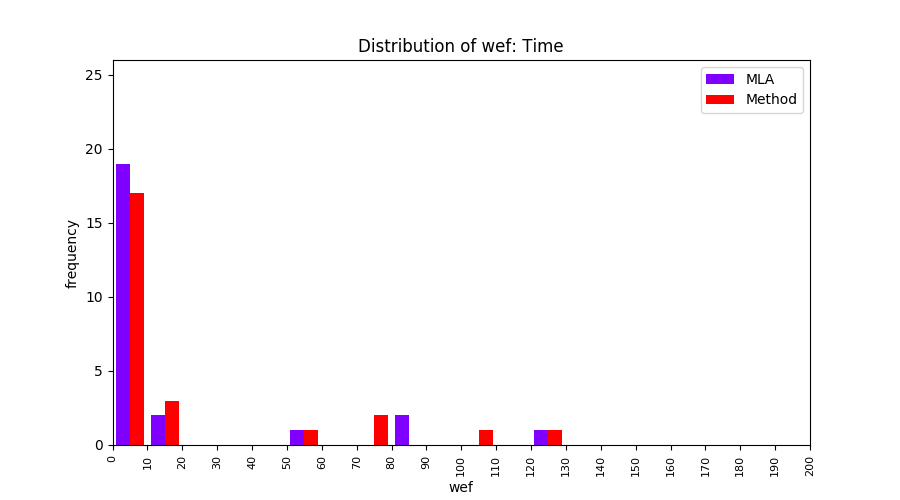
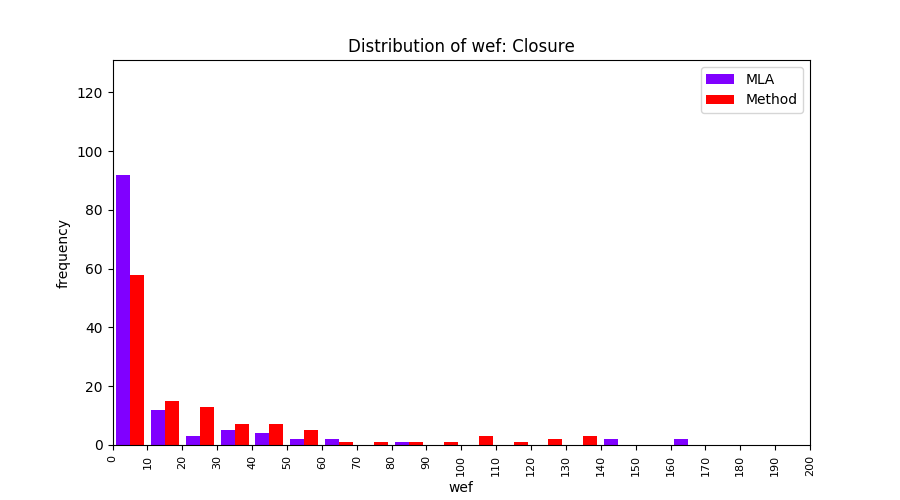
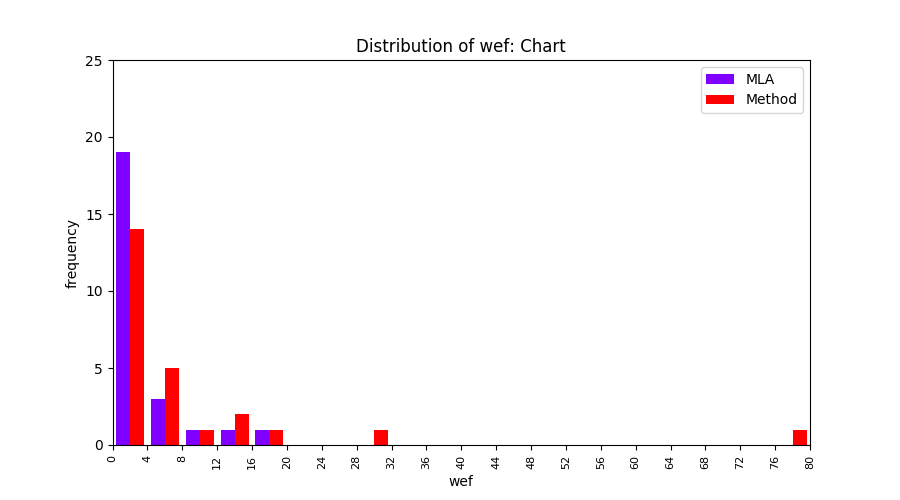
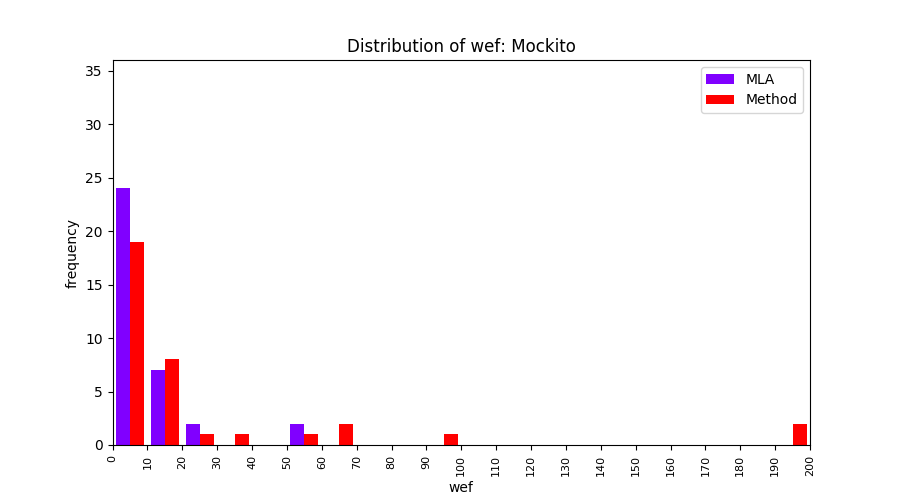
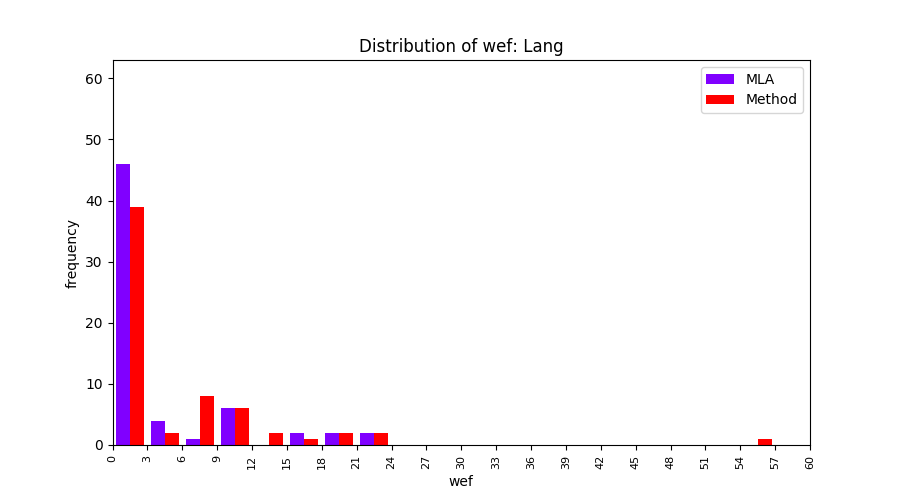
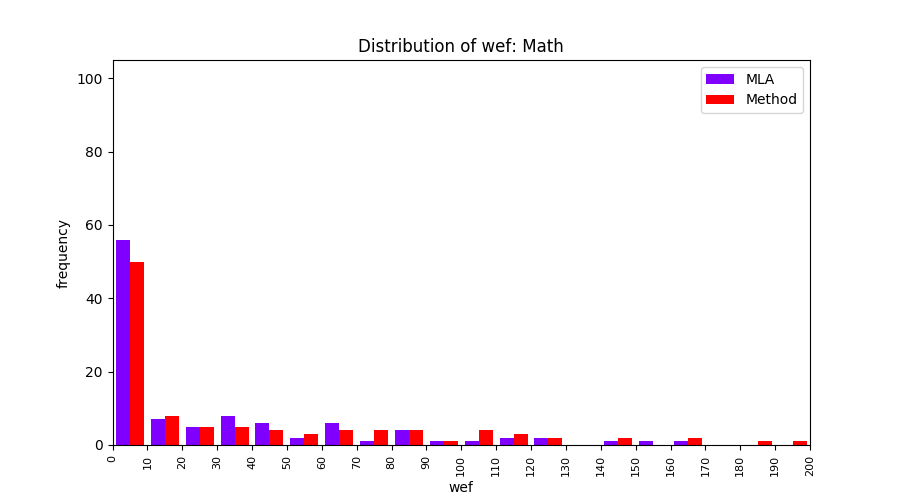
FLUCCS uses Method Level Aggregation on SBFL suspiciousness scores to further imporve the accuracy of fault localization. Impact of using Method Level Aggregation (or Method Aggregation) is shown in following histograms of wef for baseline formulas; two cases, with and without Method Aggregation, are described in the histograms side by side.
| ER1a | ER1b | ER5a | ER5b | ER5c |
| gp02 | gp03 | gp13 | gp19 | |
| ochiai | jaccard |
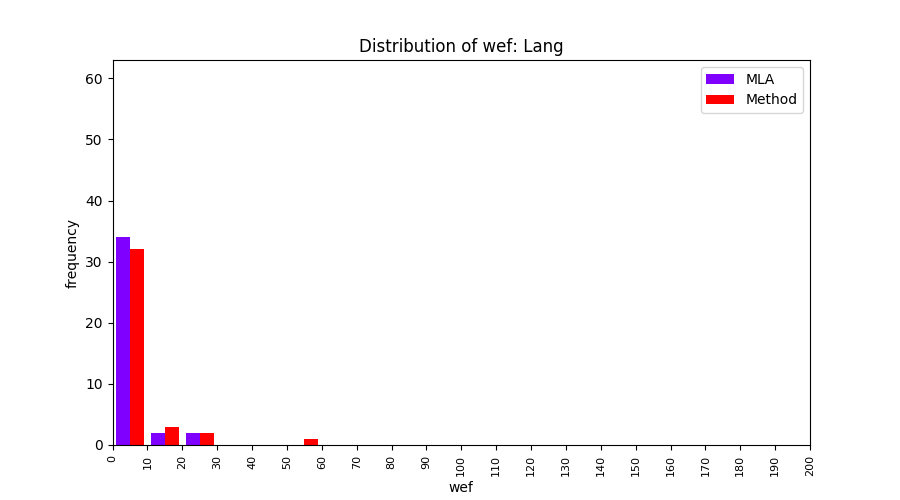
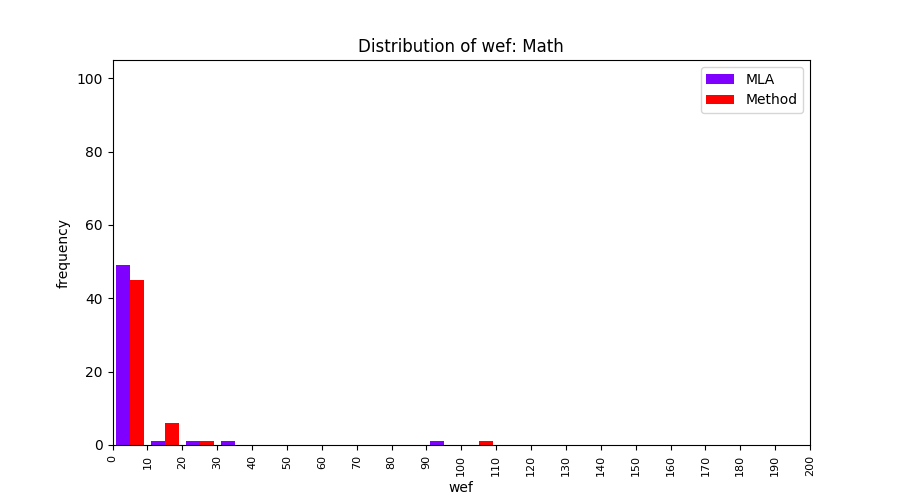
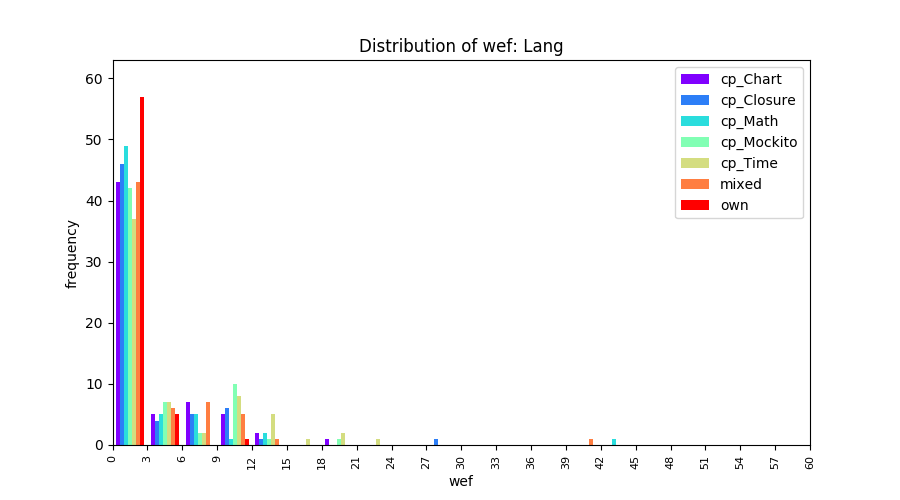
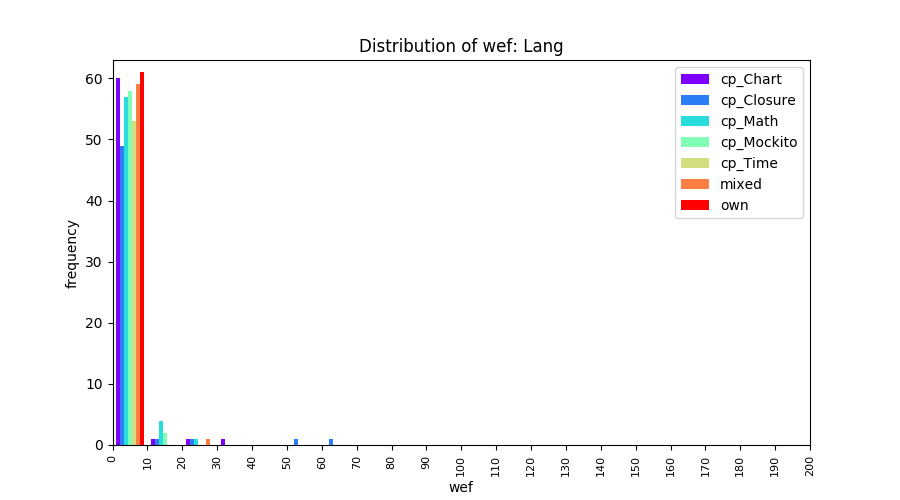
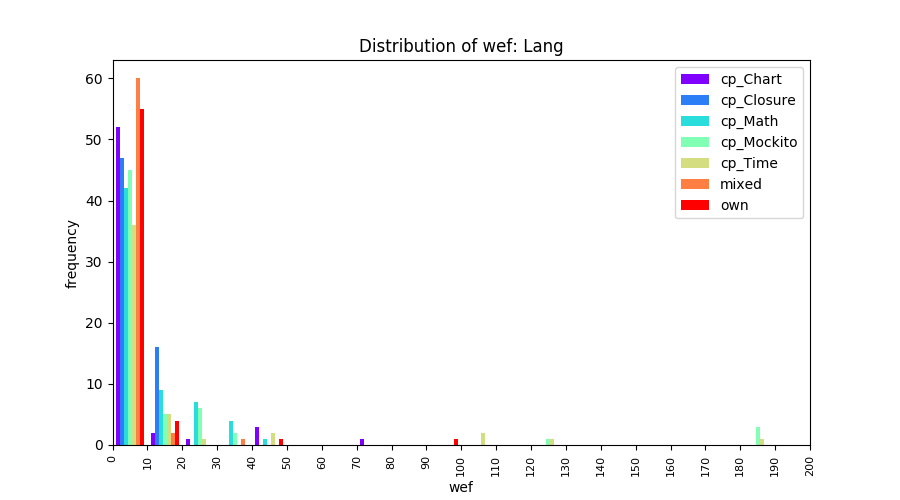
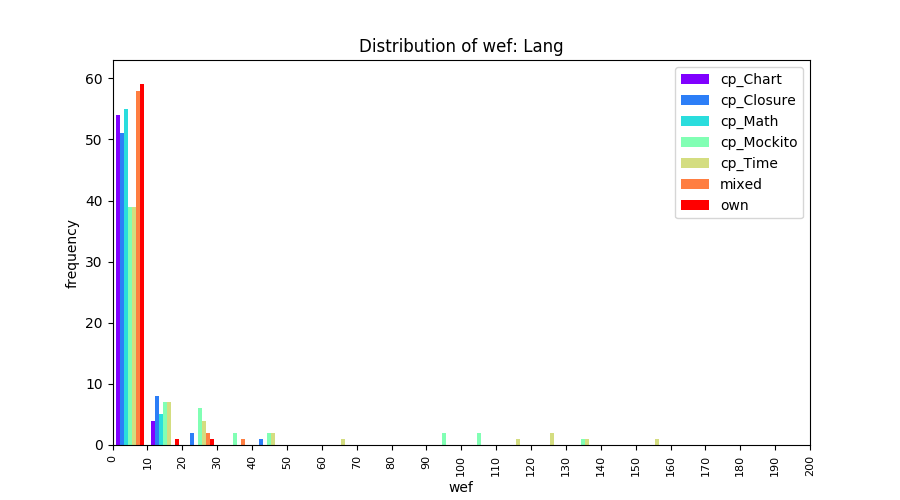
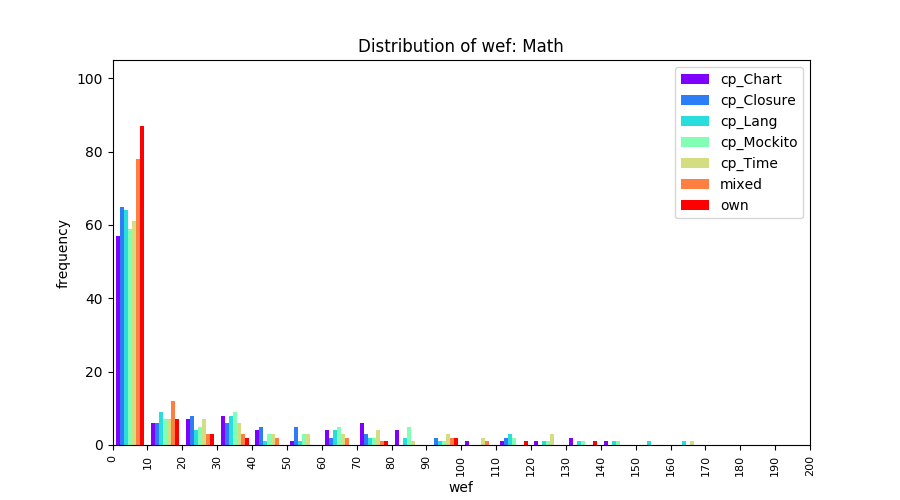
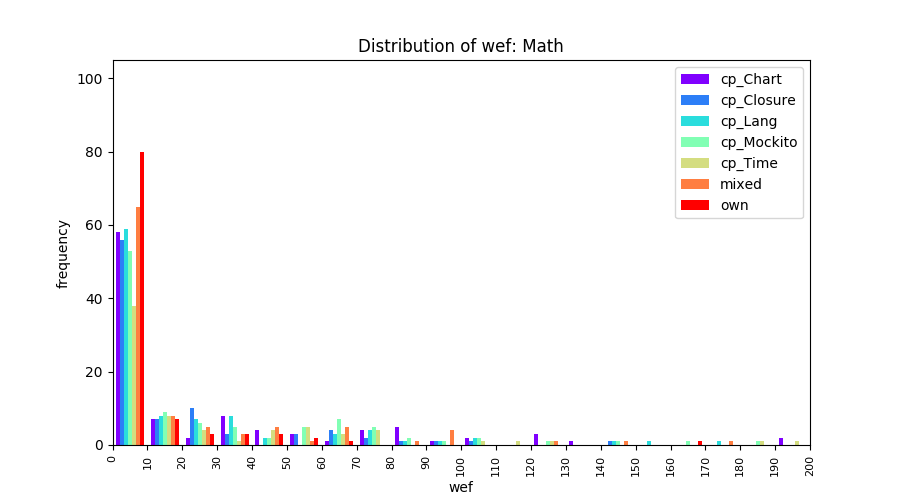
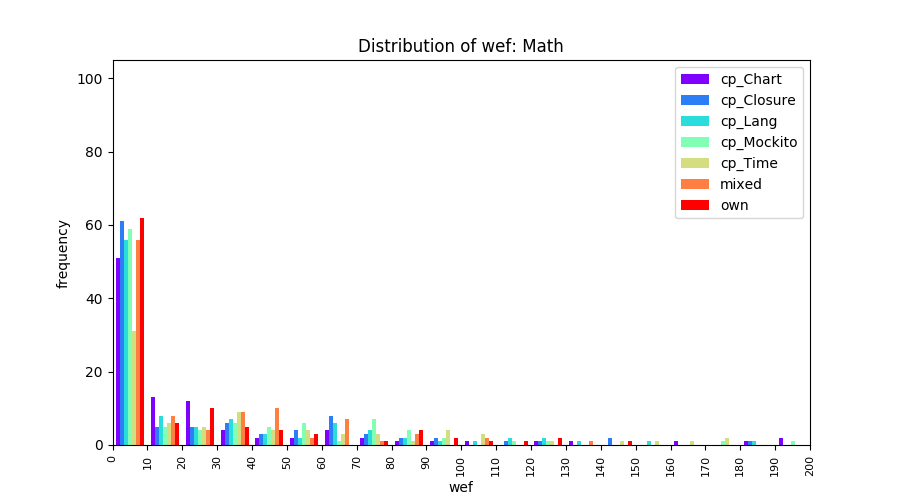
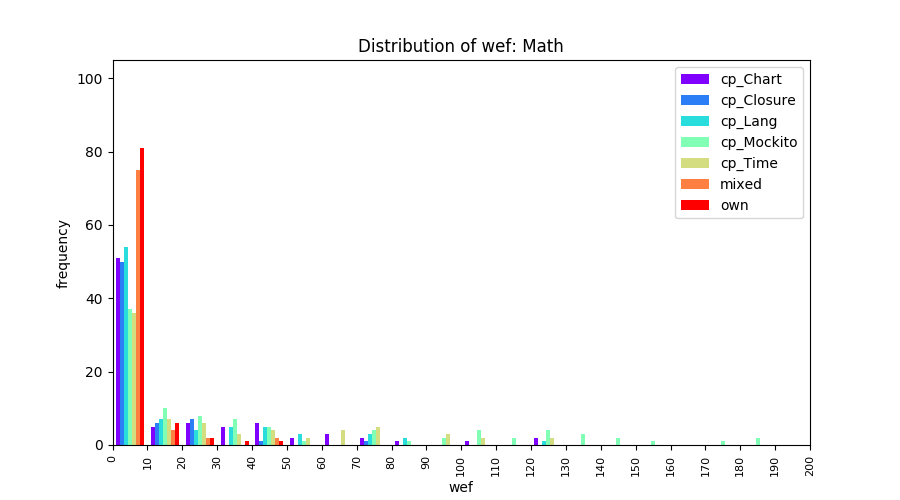
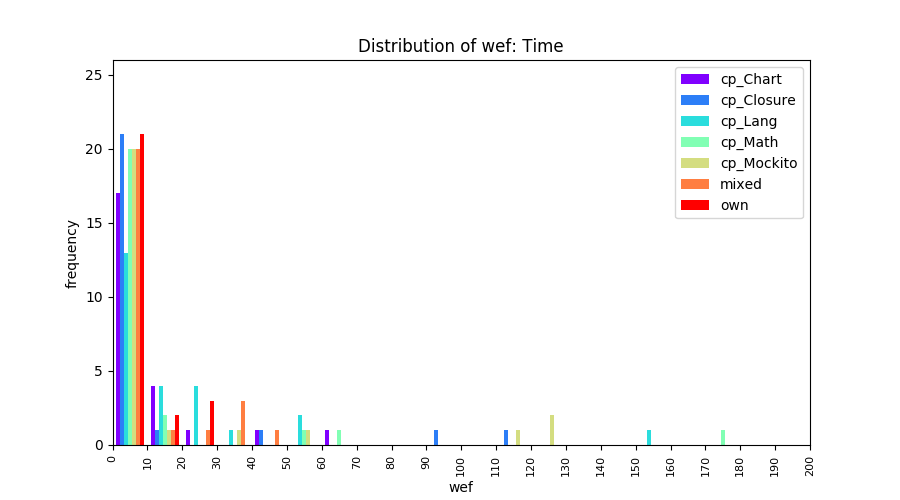
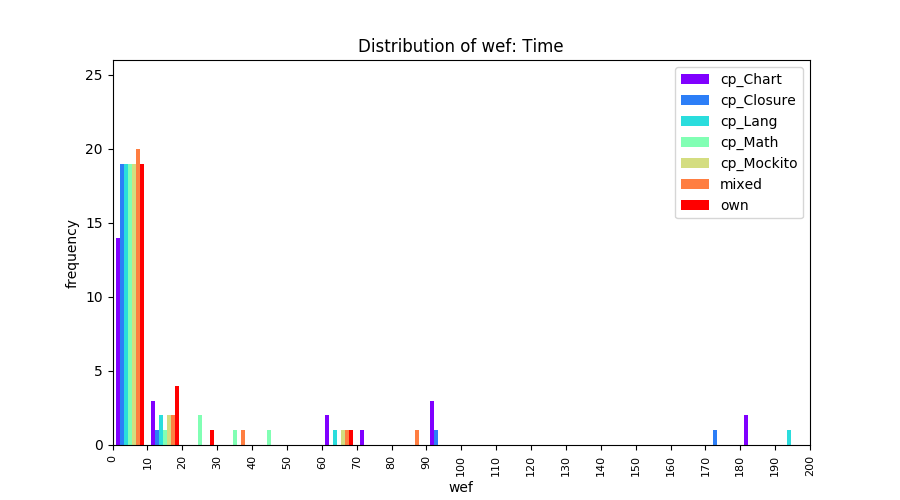
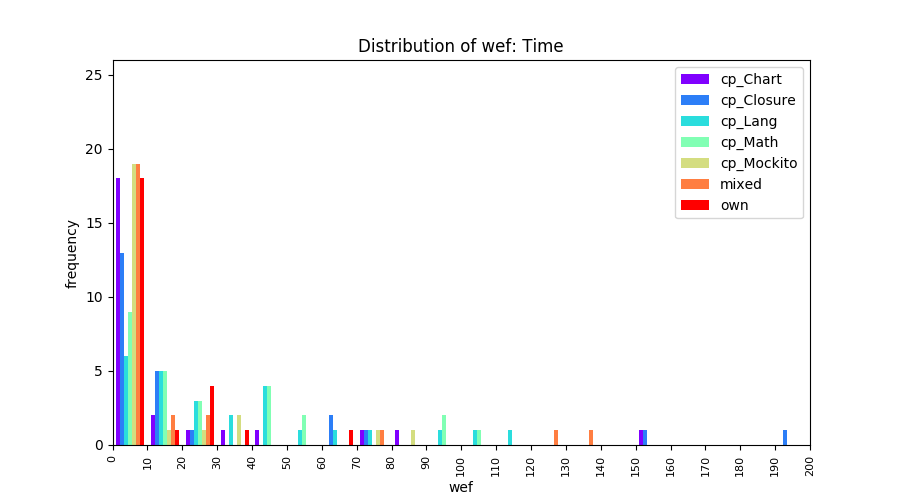
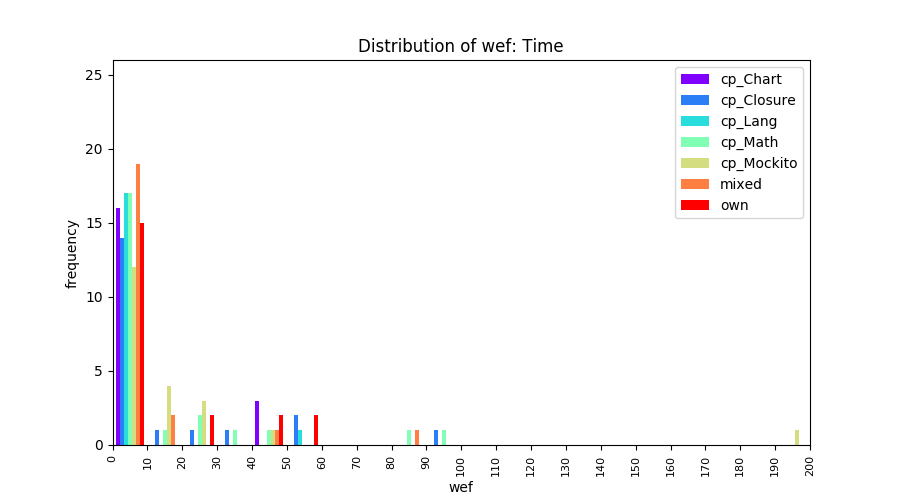
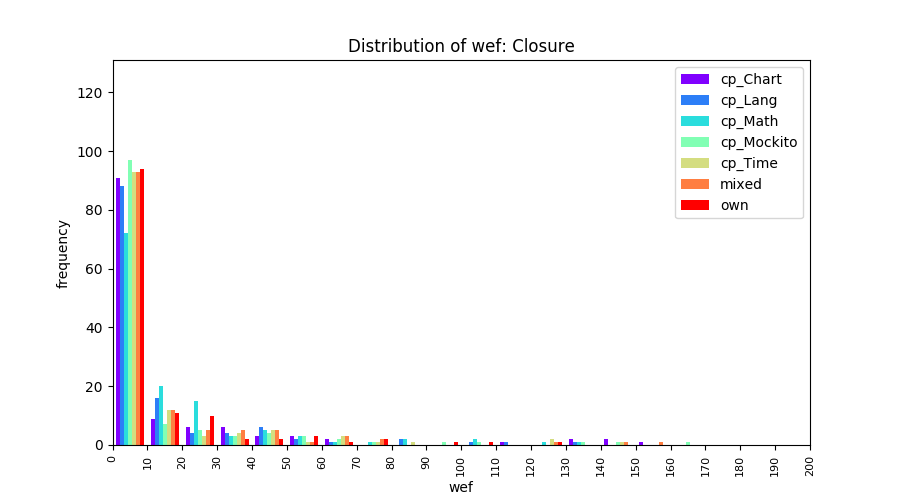
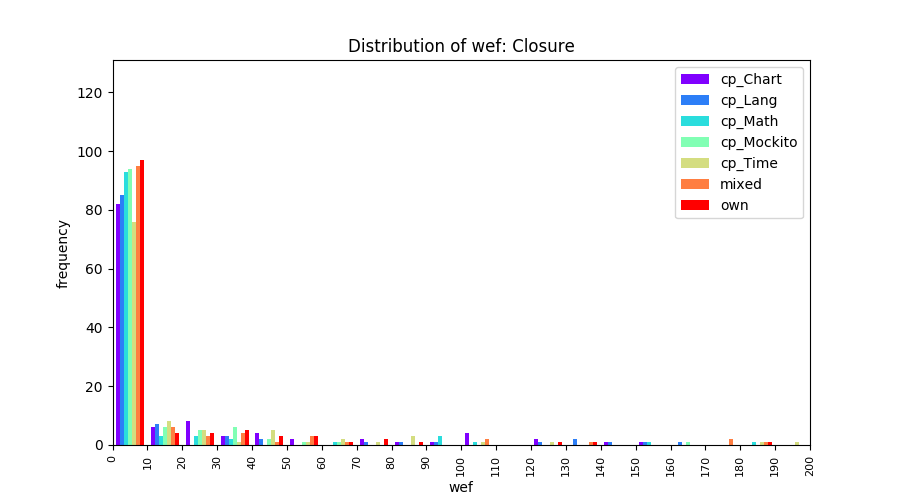
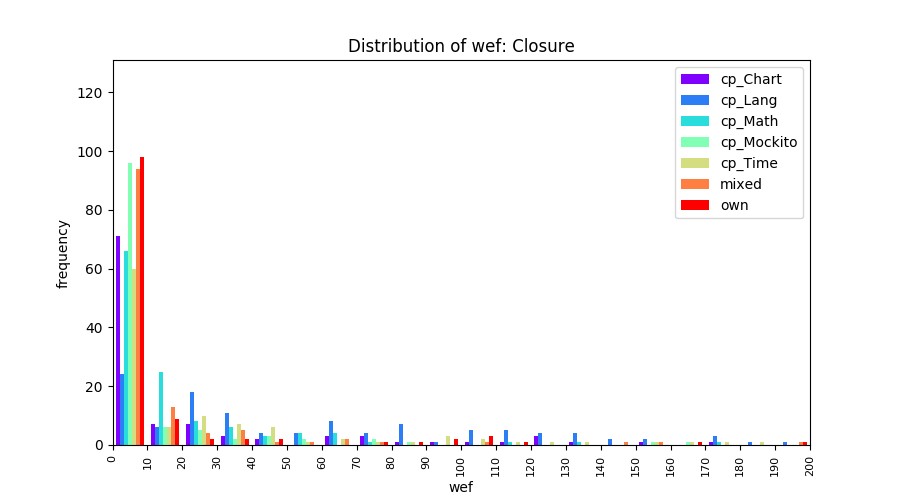
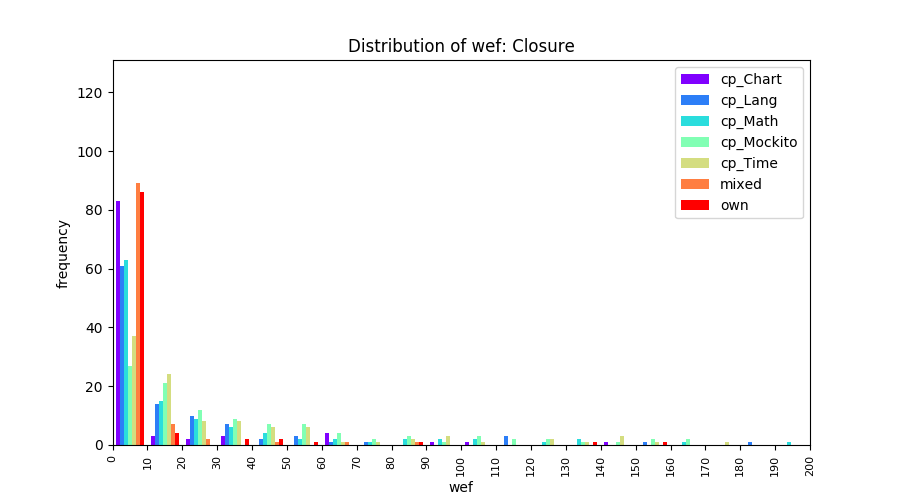
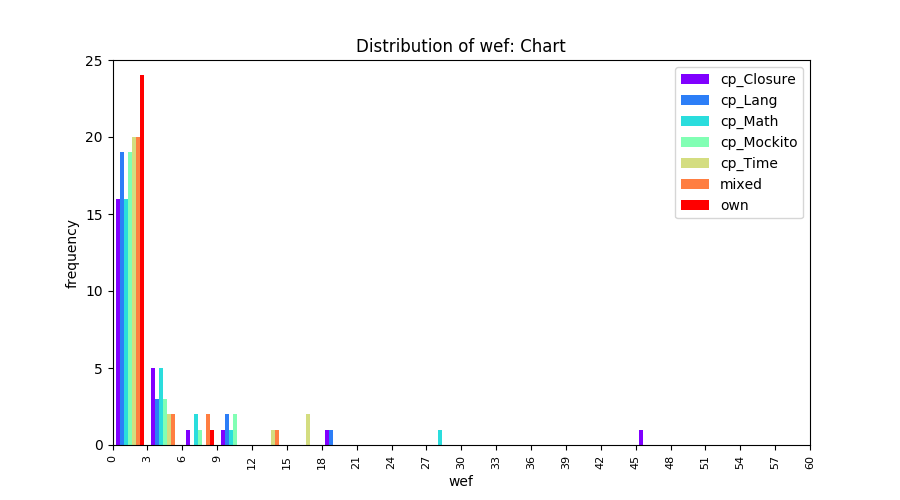
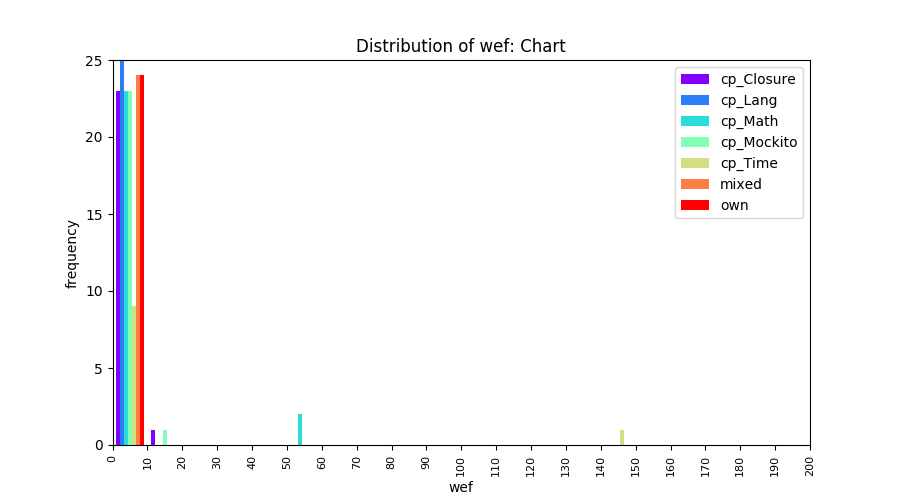
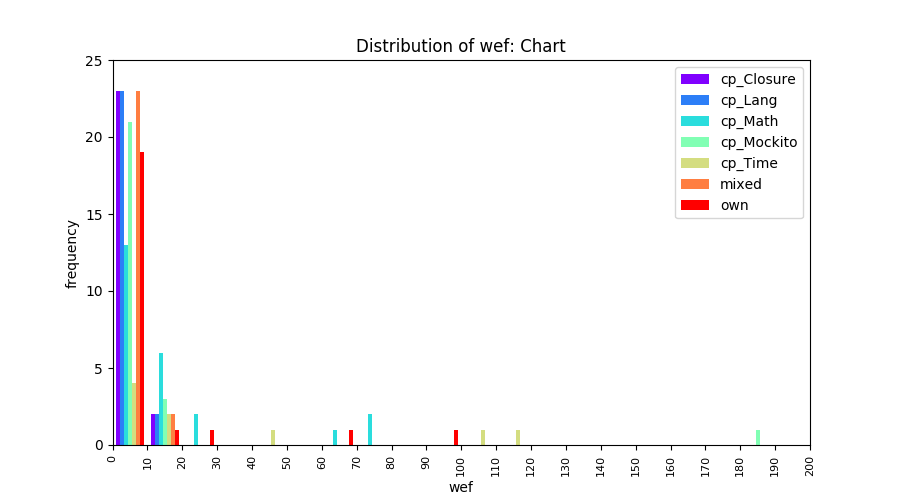
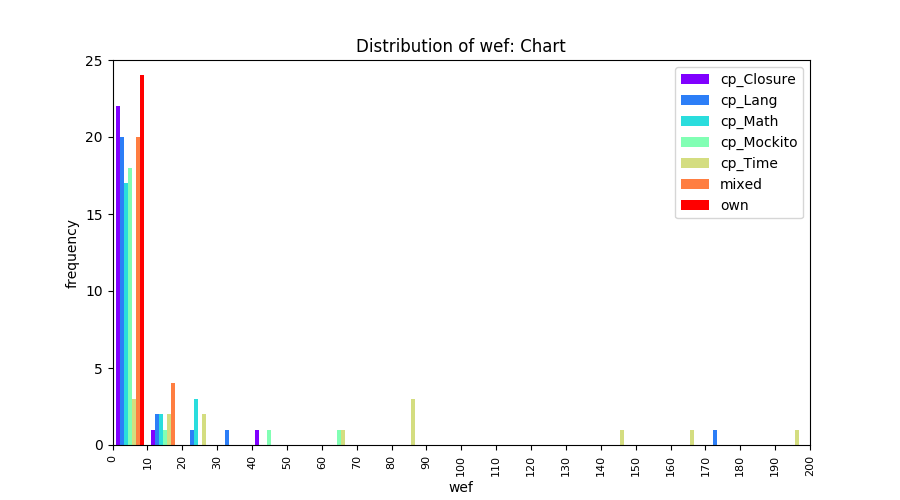
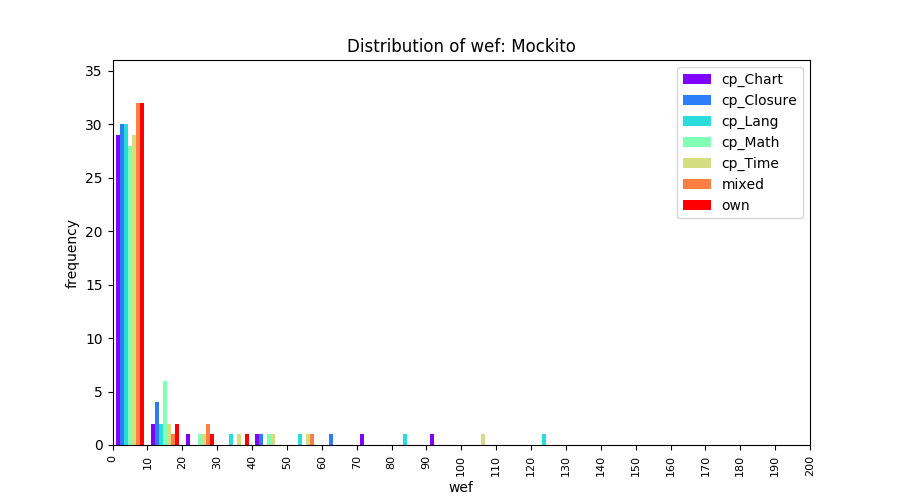
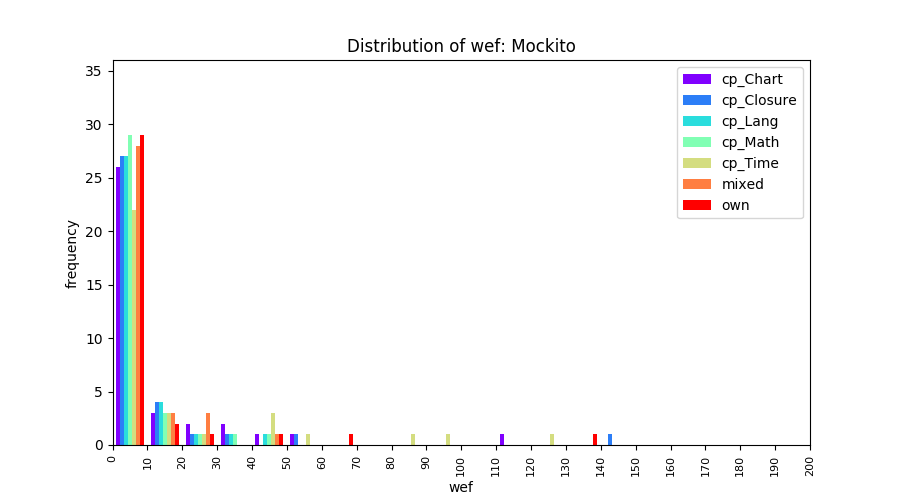
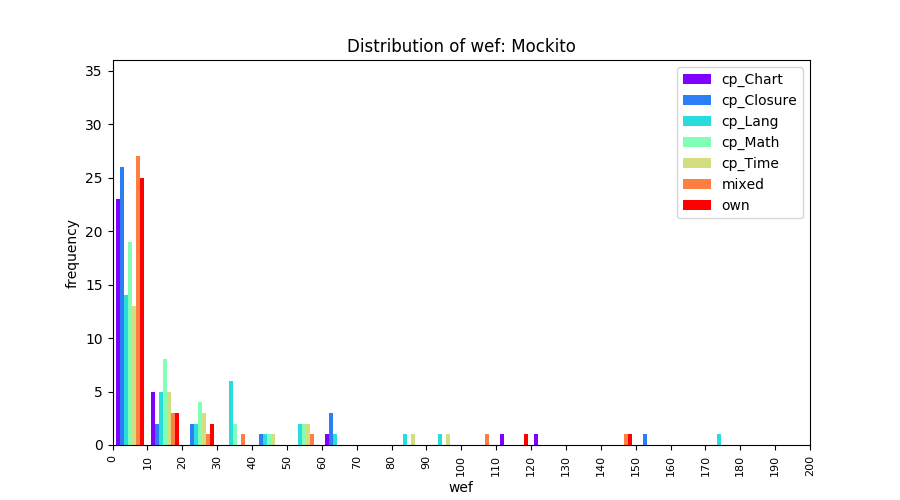
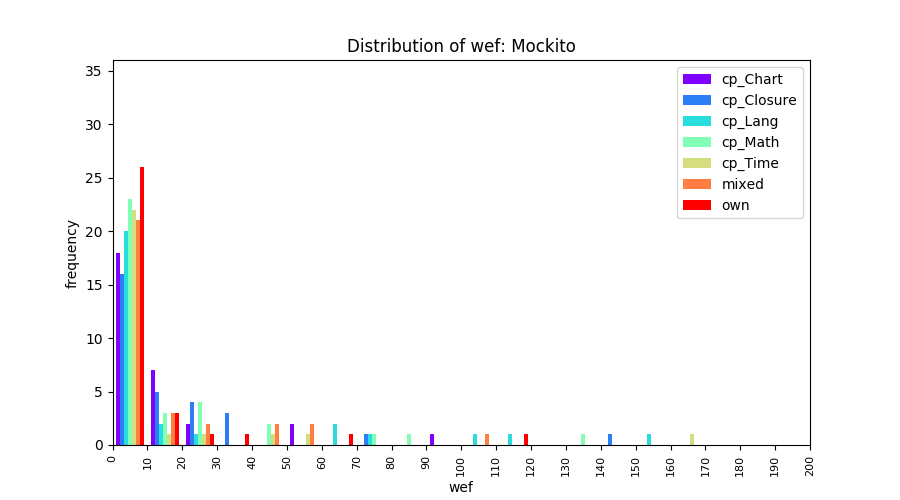
Above results have been obtained by using the data set which composes of fault data from six different projects (Lang, Math, Time, Closure, Chart, Mockito). Here, we show the cross-project validity for these projects using four different learning mechanisms.
| Lang |
| Math |
| Time |
| Closure |
| Chart |
| Mockito |
All of these histograms are limited to wef values which are smaller or equal to 200 due to hardness of visualization when including large values. If the technique failed to localize any faults within top 200, no histograms are appeared in the figure.
Artifact
An artifact of FLUCCS, named *defects4j-fluccs*, contains the implementation of FLUCCS as well as the dataset used to evaluate it in the accompanying paper. Data sets generated by FLUCCS consist of suspiciousness scores from existing SBFL formulas as well as code and change metric values (age, churn, and complexity). This artifact is uploaded at here.
FLUCCS Extension
Full results of additional experiments on FLUCCS, i.e., cross-project, gradual cross-project, and feature importance analysis, are uploaded here