Amortised Deep Parameter Optimisation of GPGPU Work Group Size for OpenCV
This page is supplementary to the paper entitled "Amortised Deep Parameter Optimisation of GPGPU Work Group Size for OpenCV", which has been presented at the International Symposium on Search-Based Software Engineering 2016. This page contains additional results that could not be reported in the paper due to page limits. The data used in the paper is also made available here to enable replication and further research on the topic.
Background
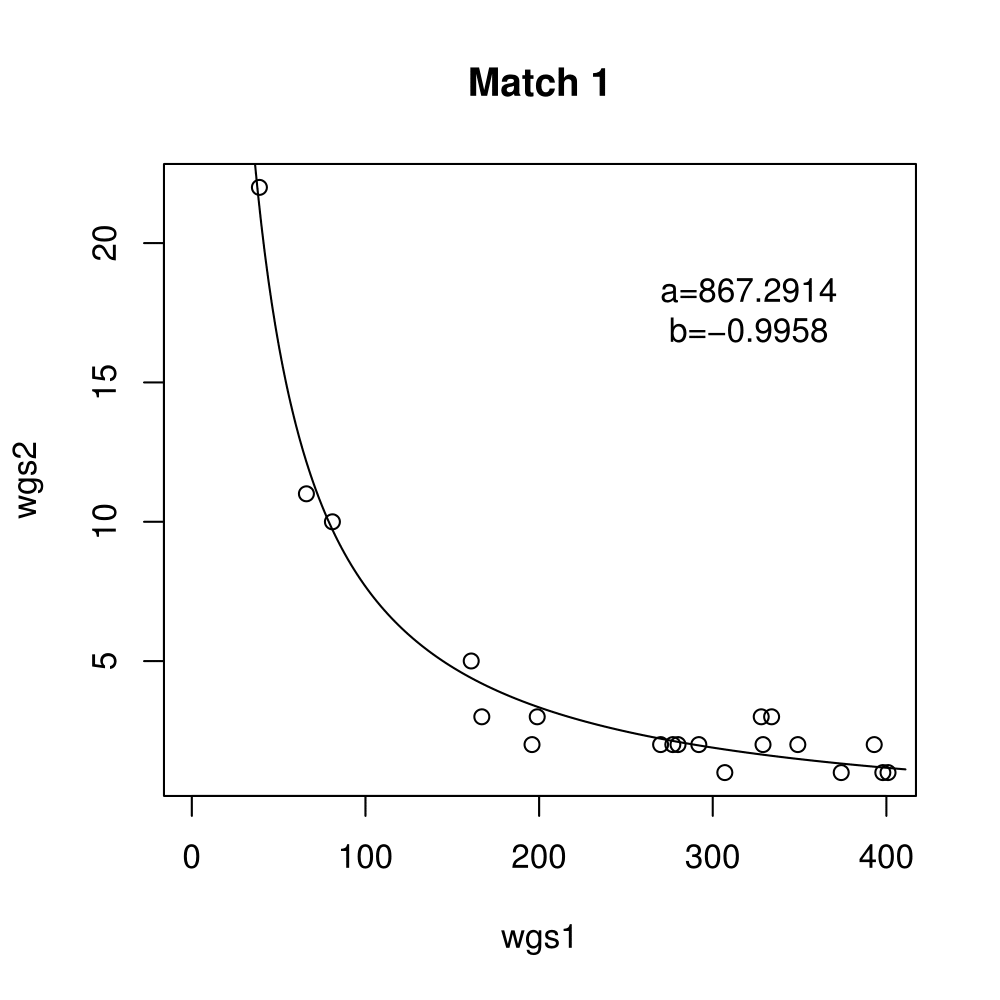
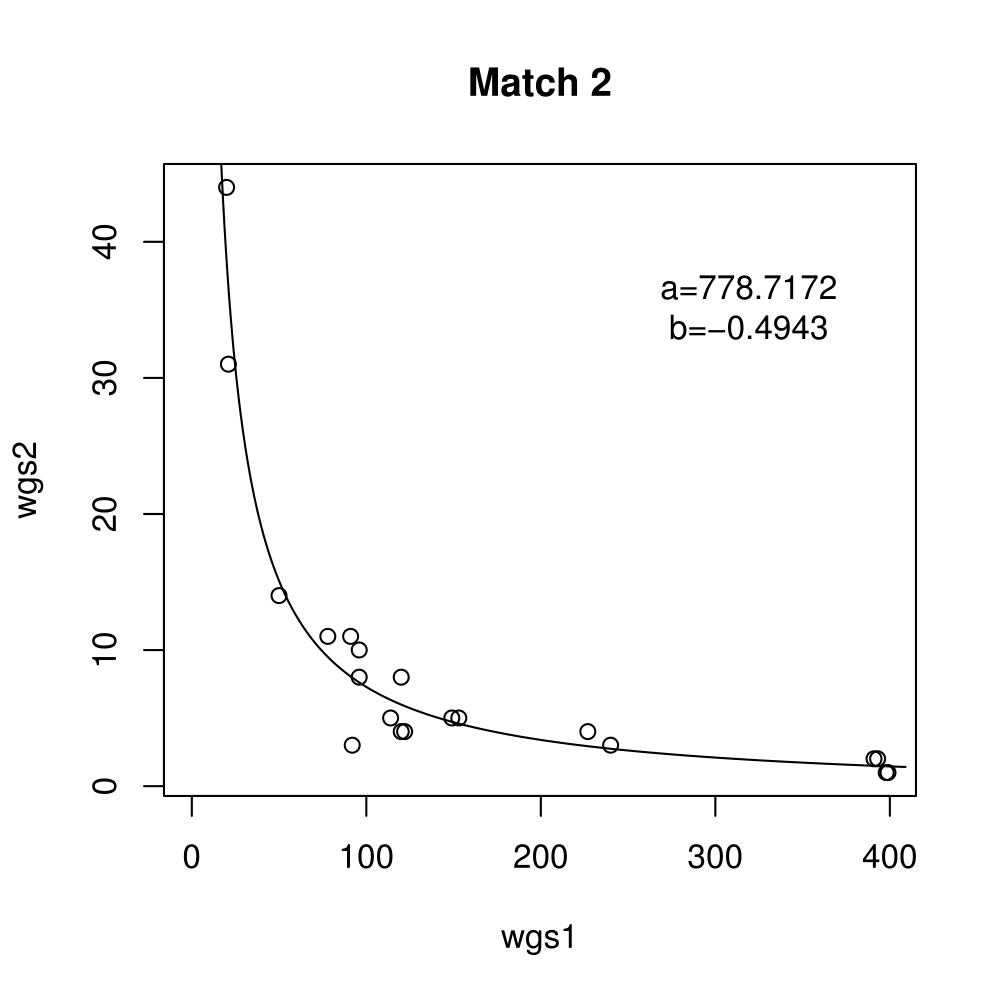
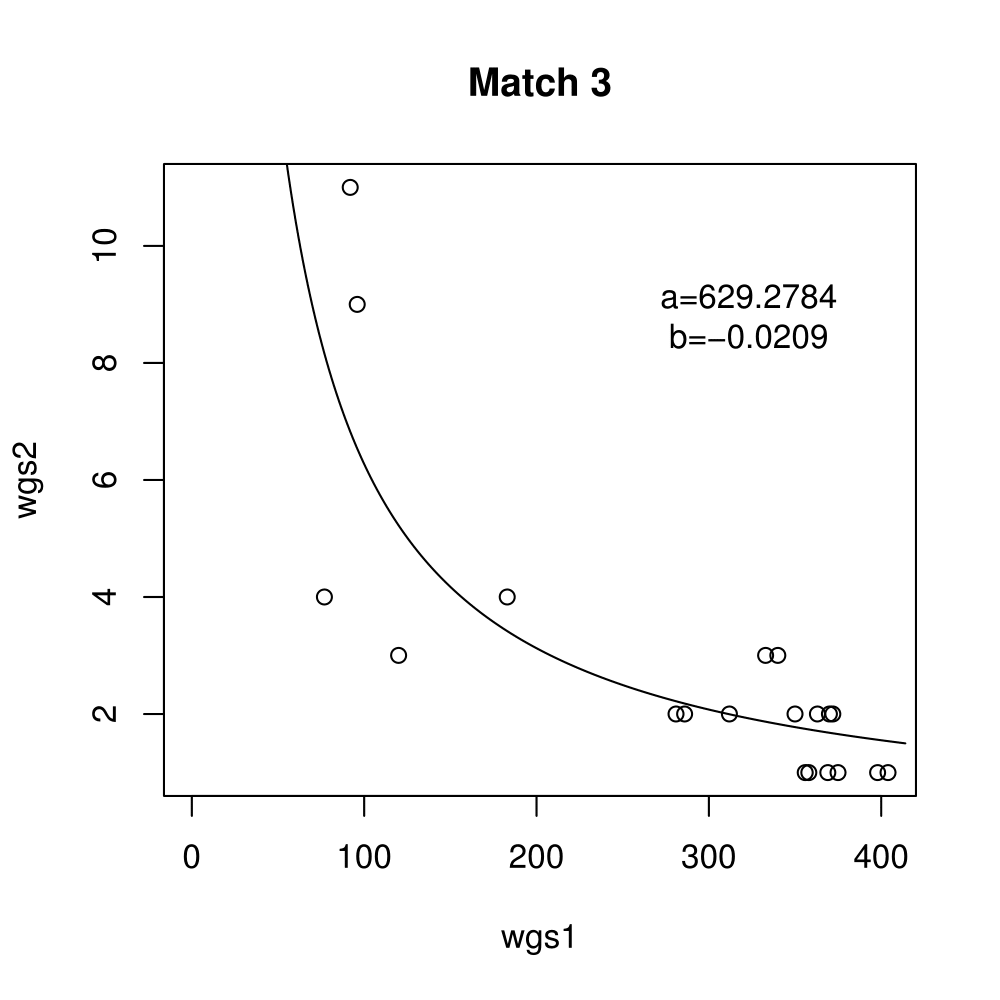
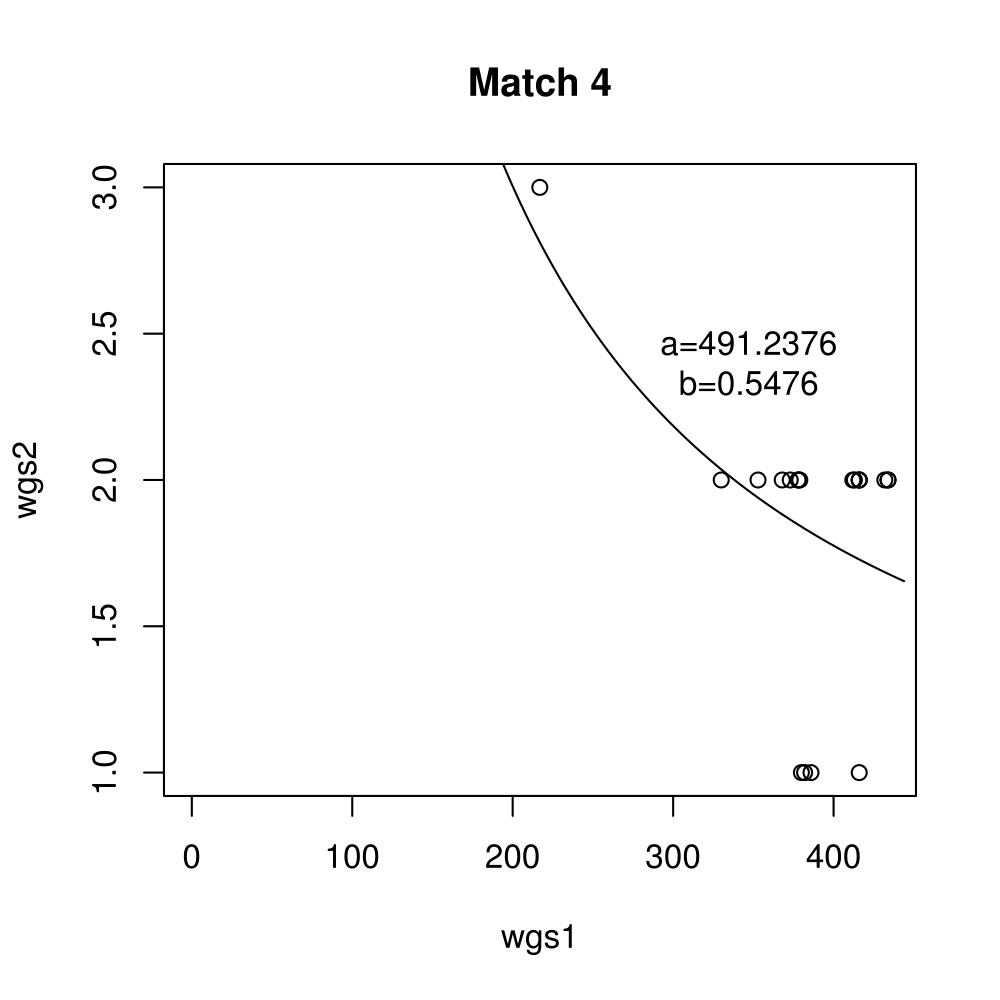
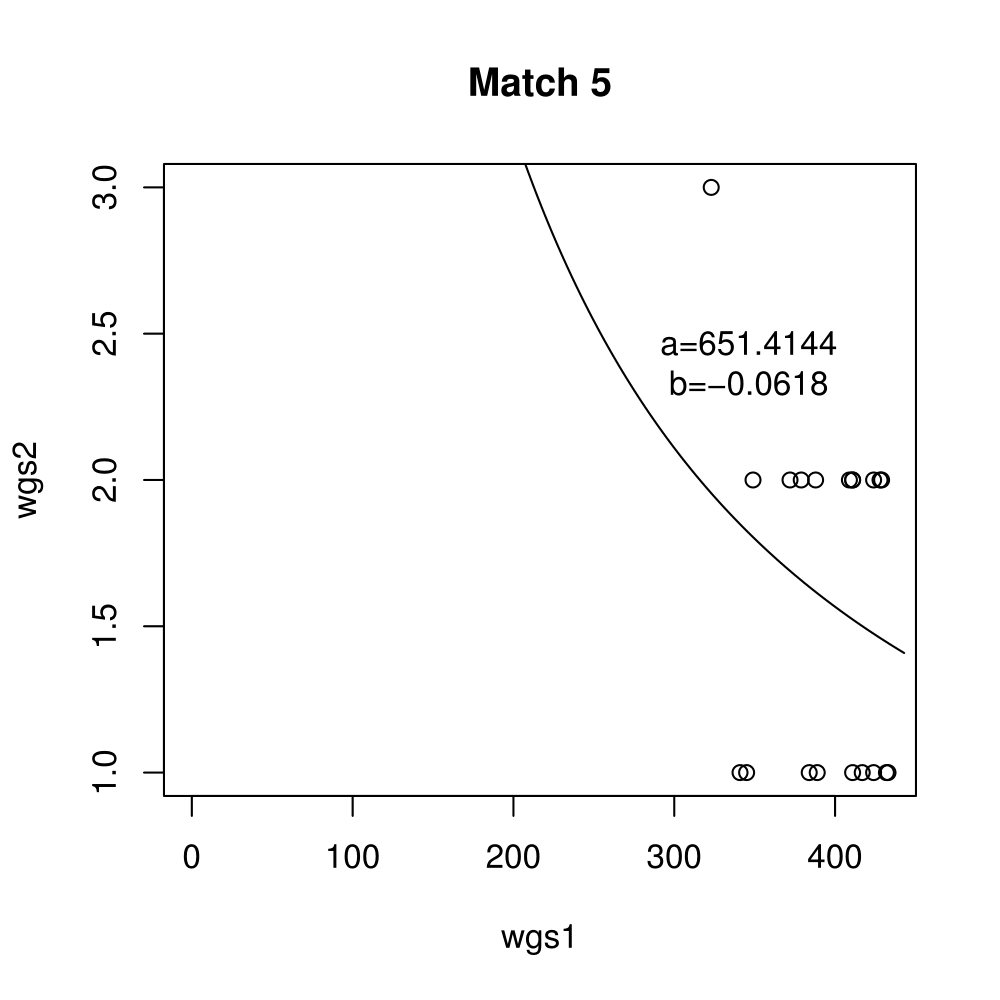
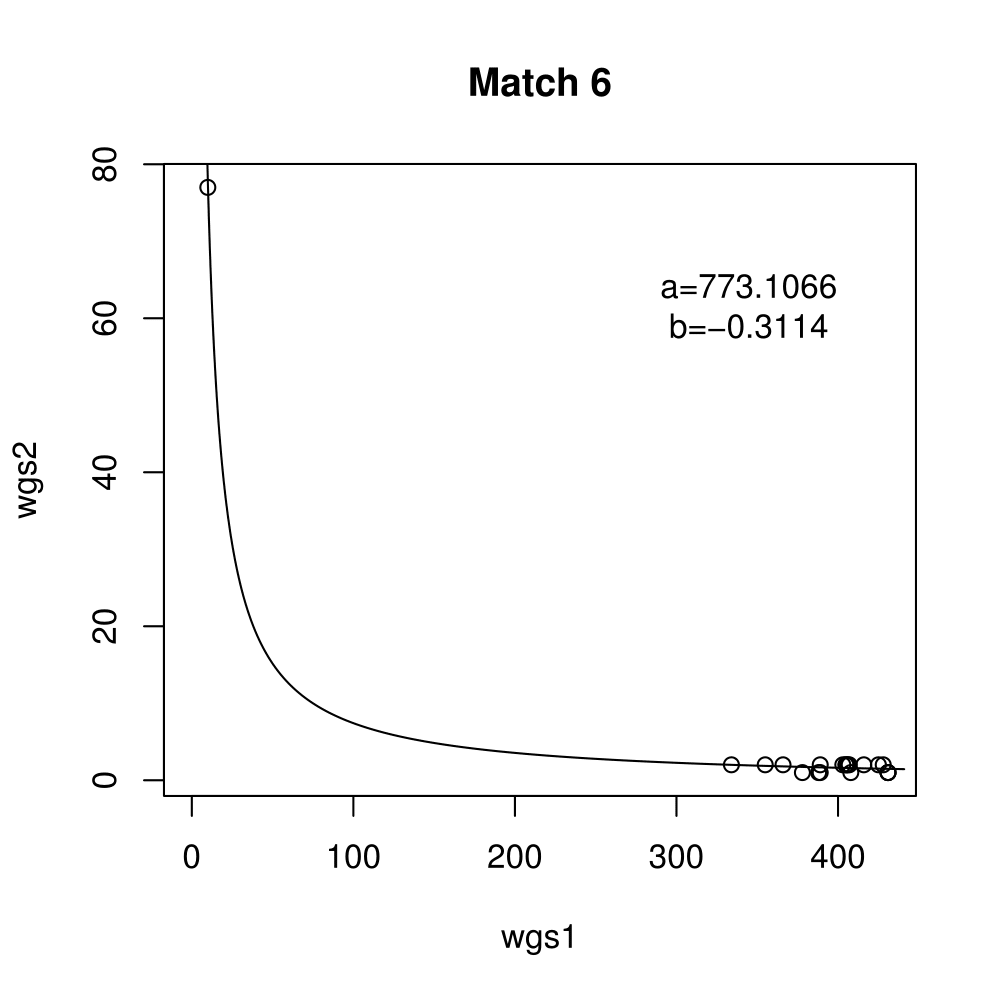
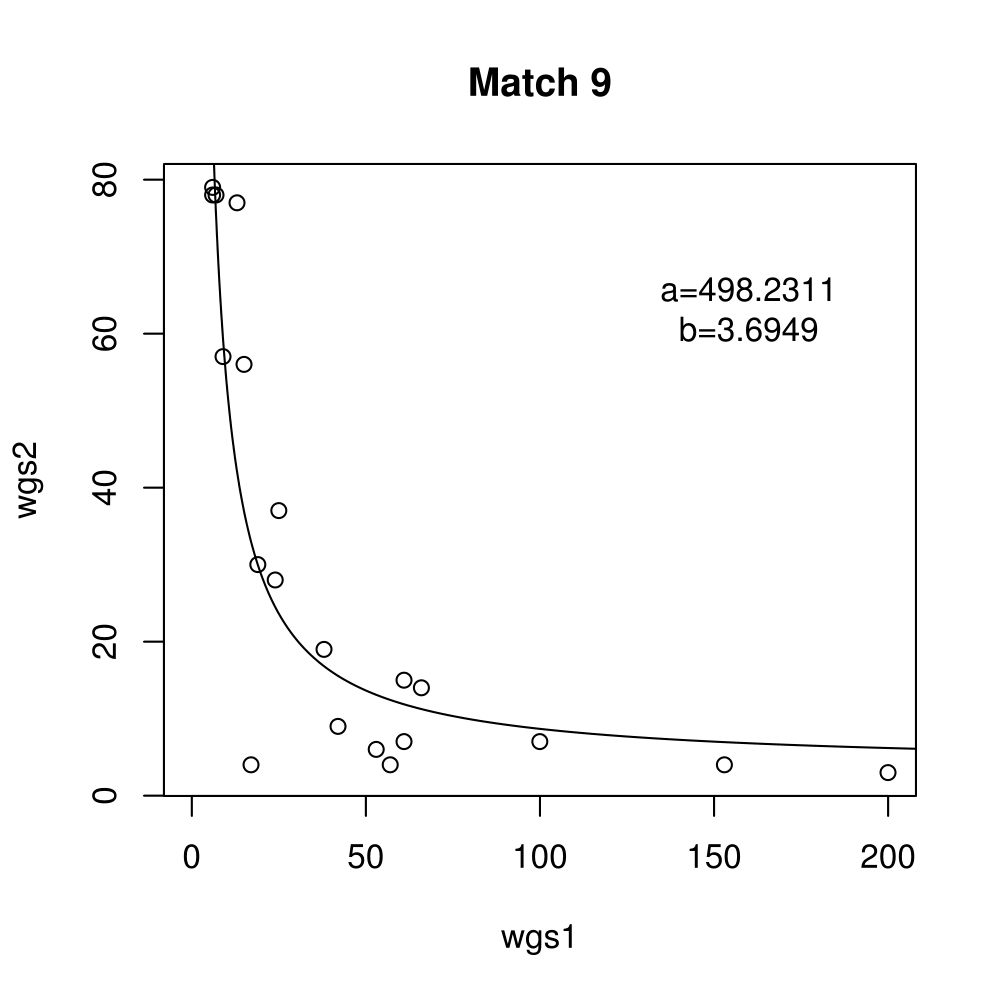
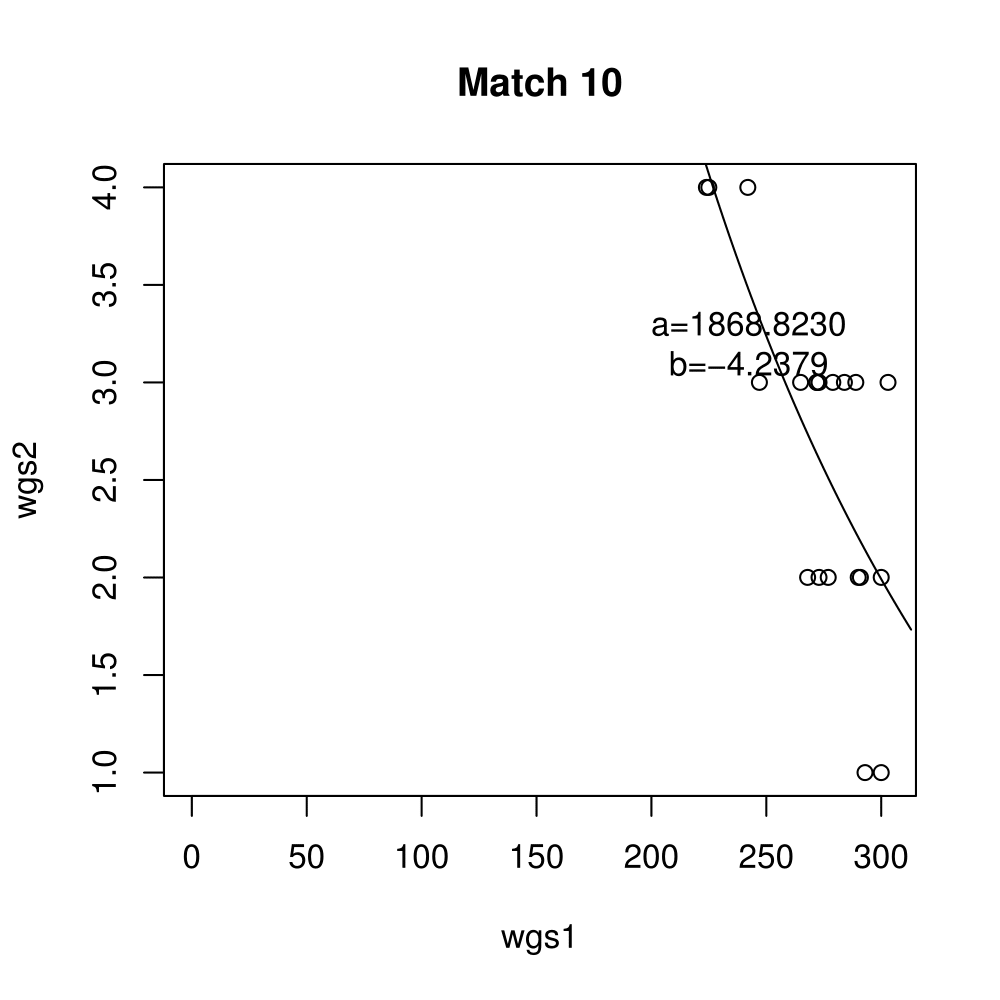
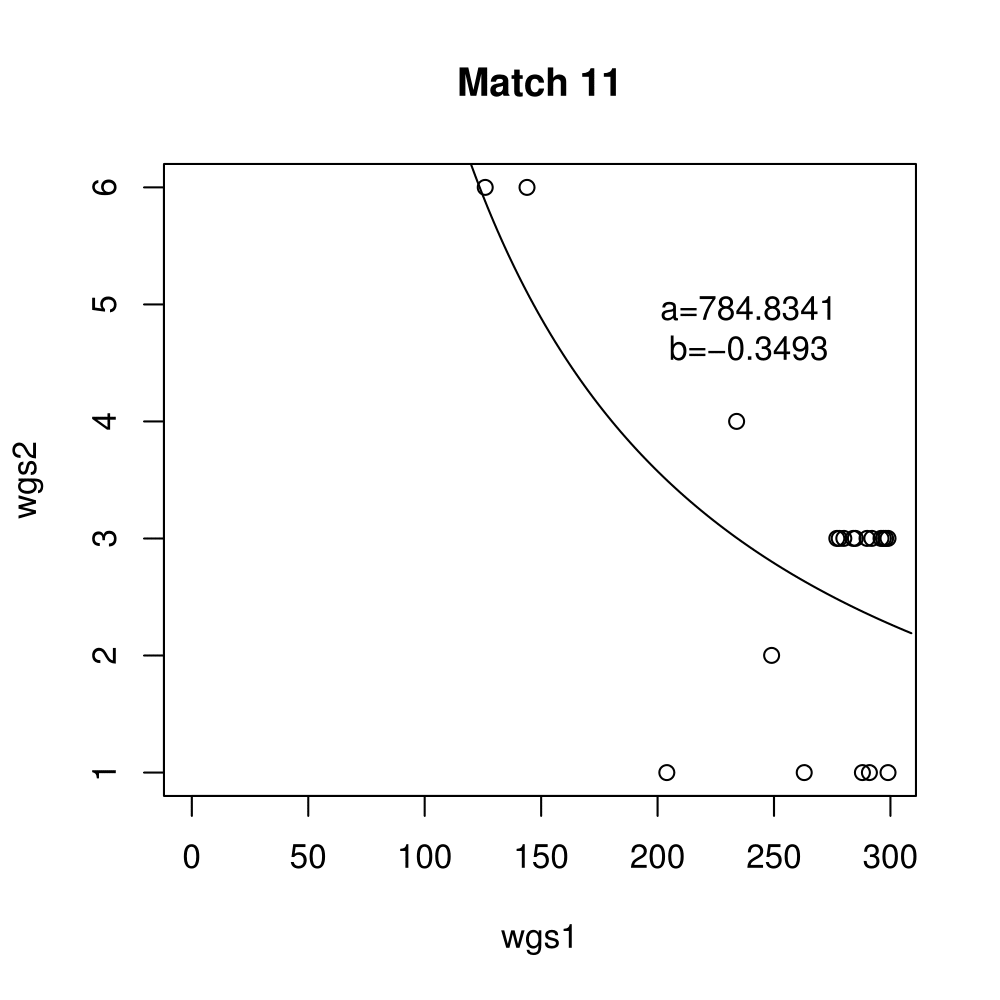
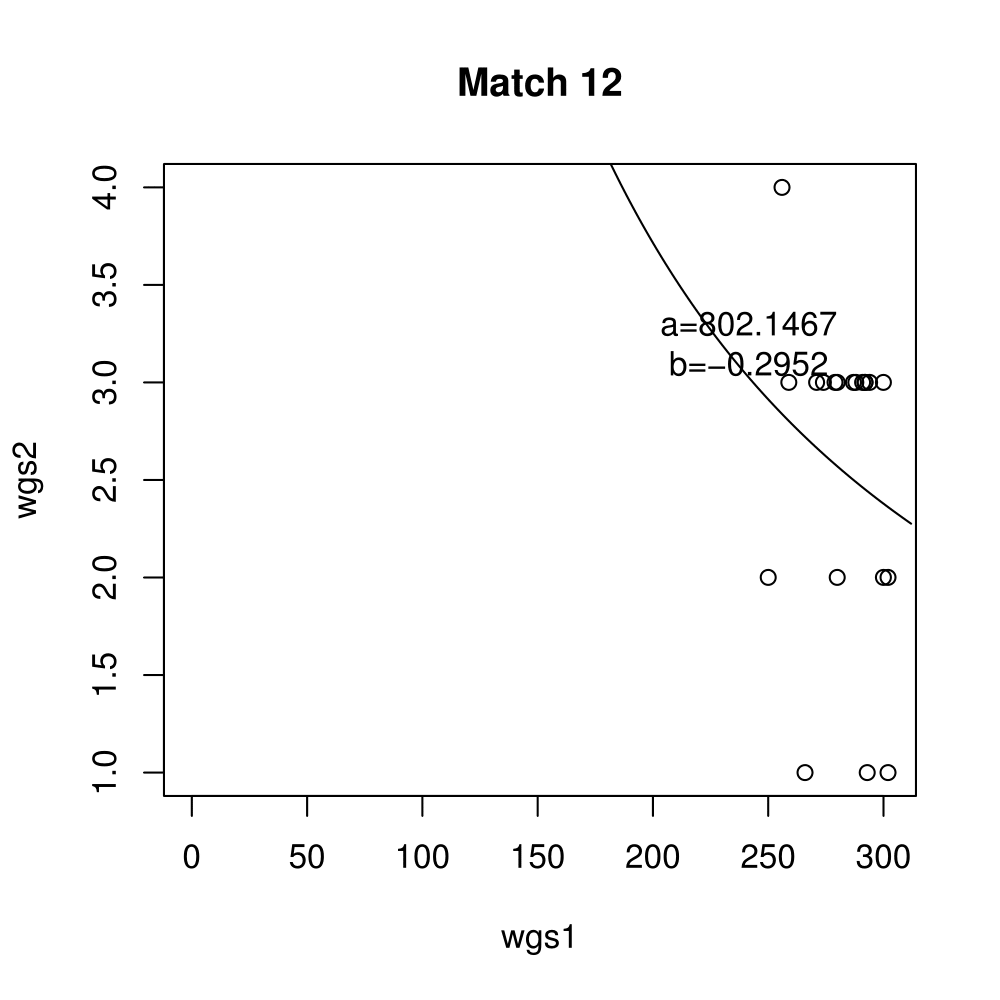
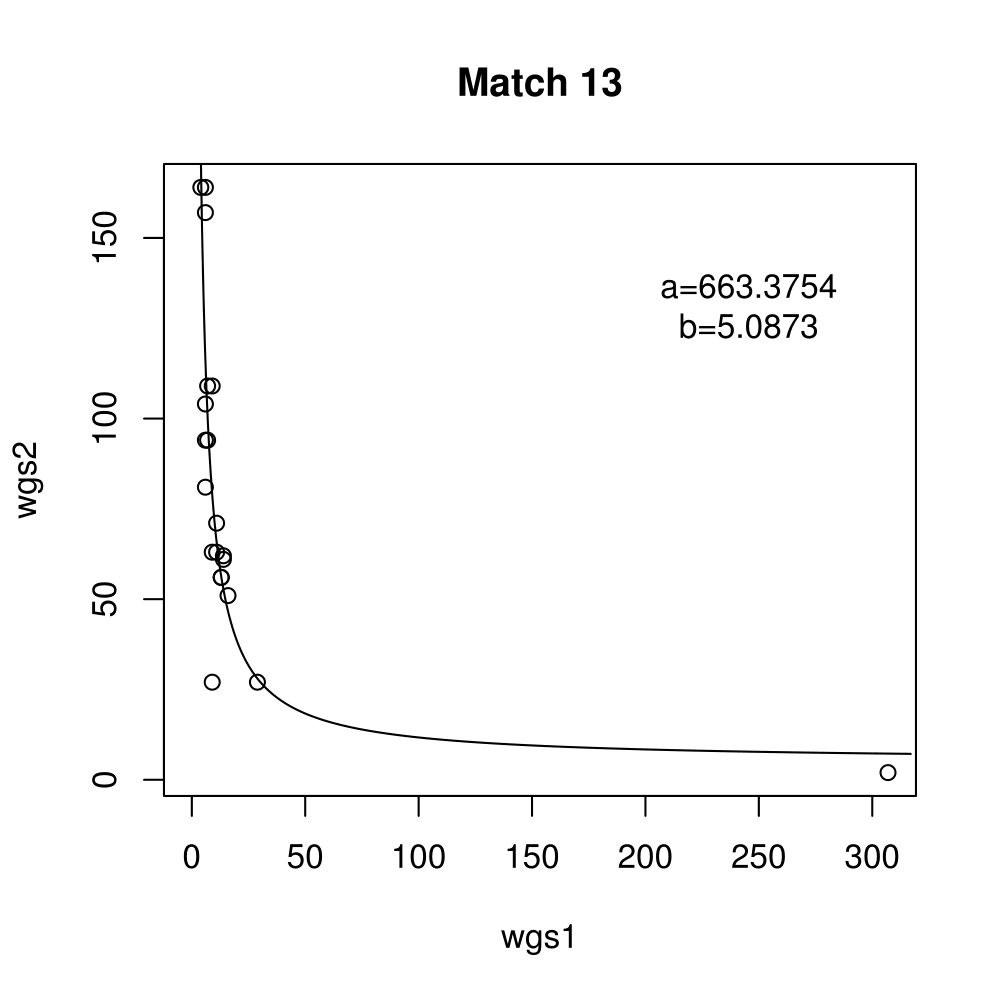
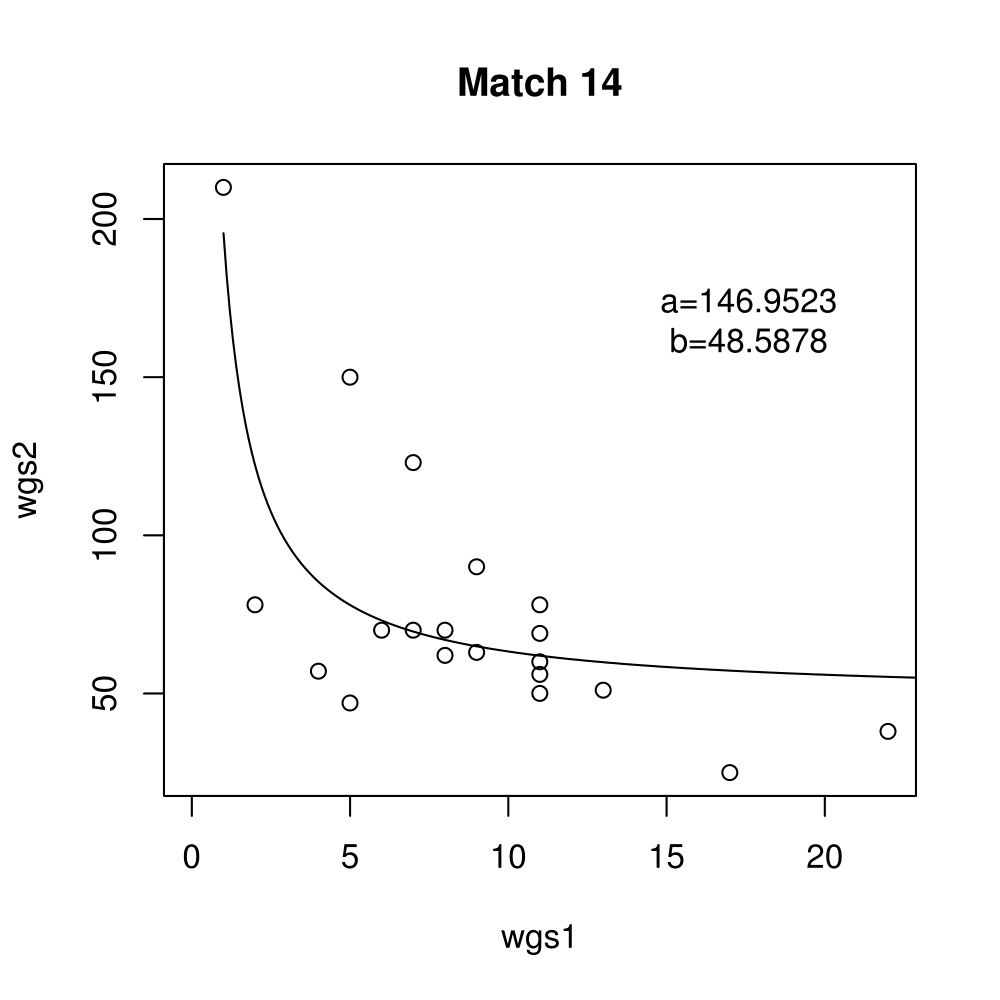
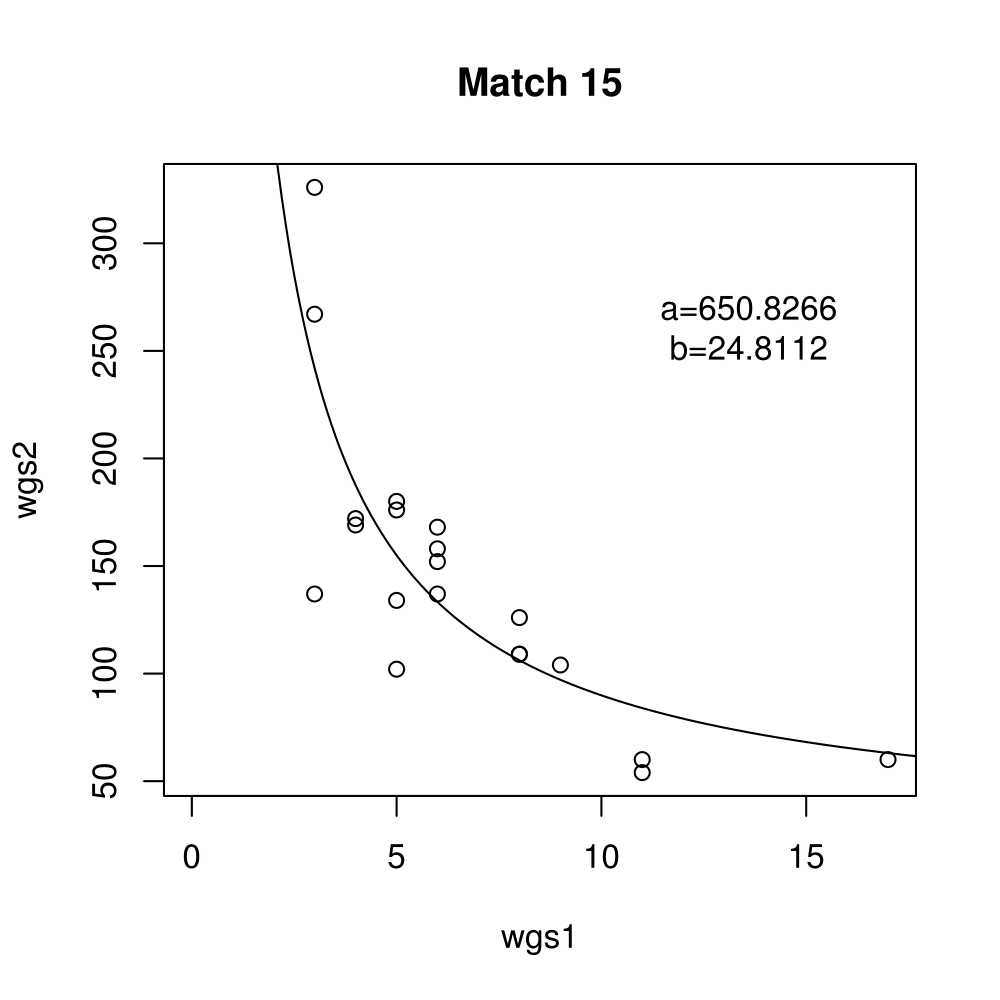
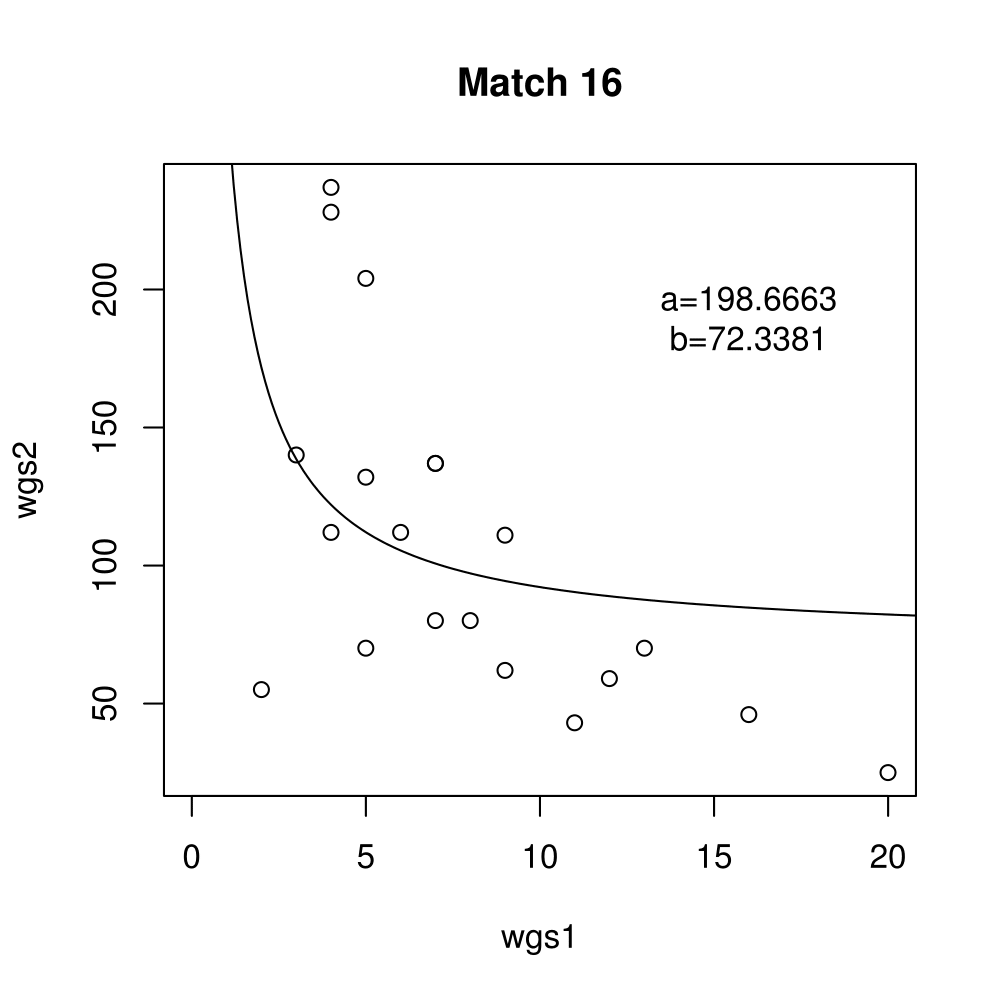
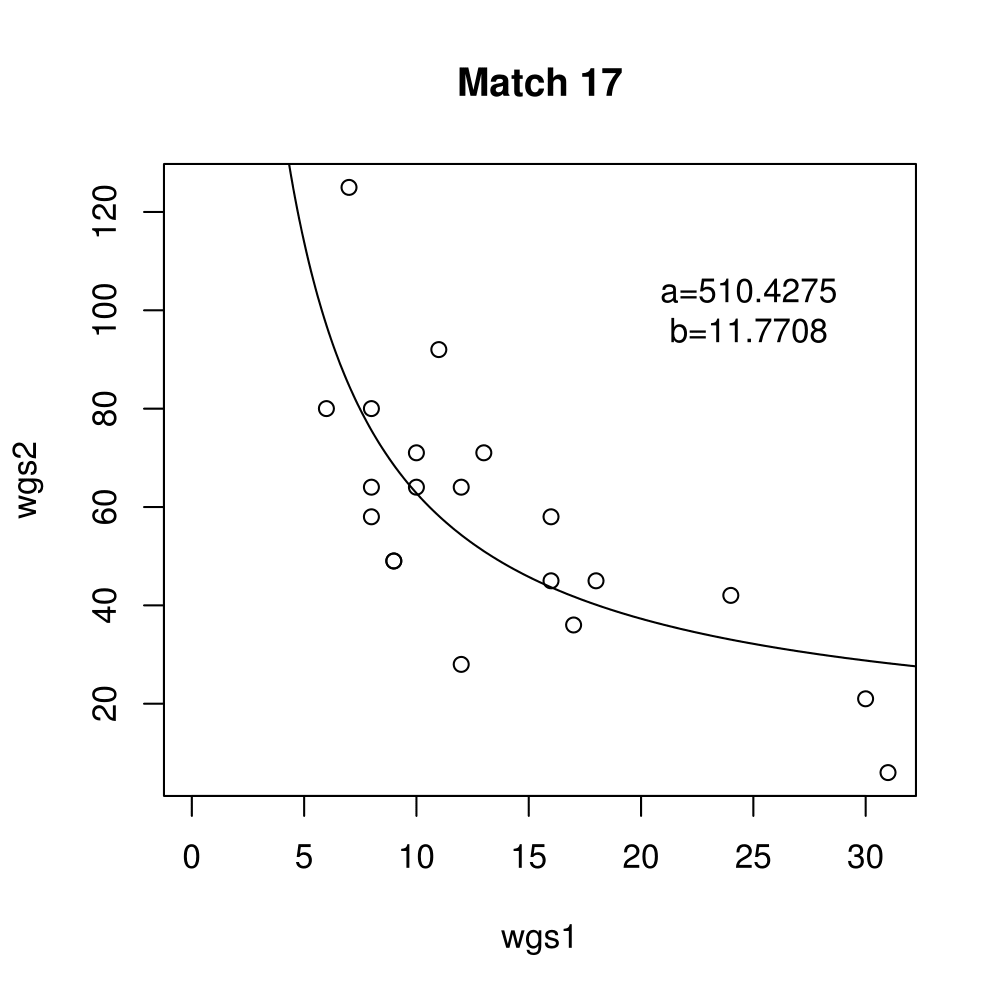
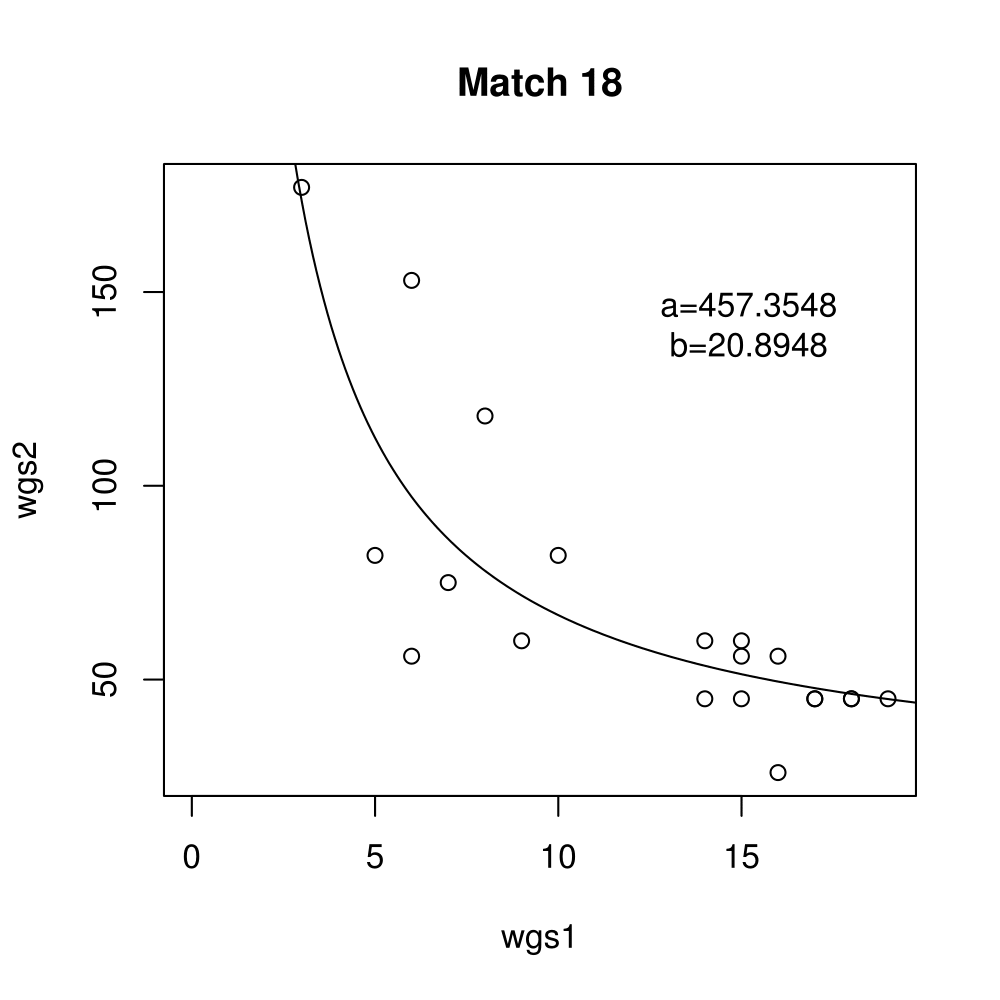
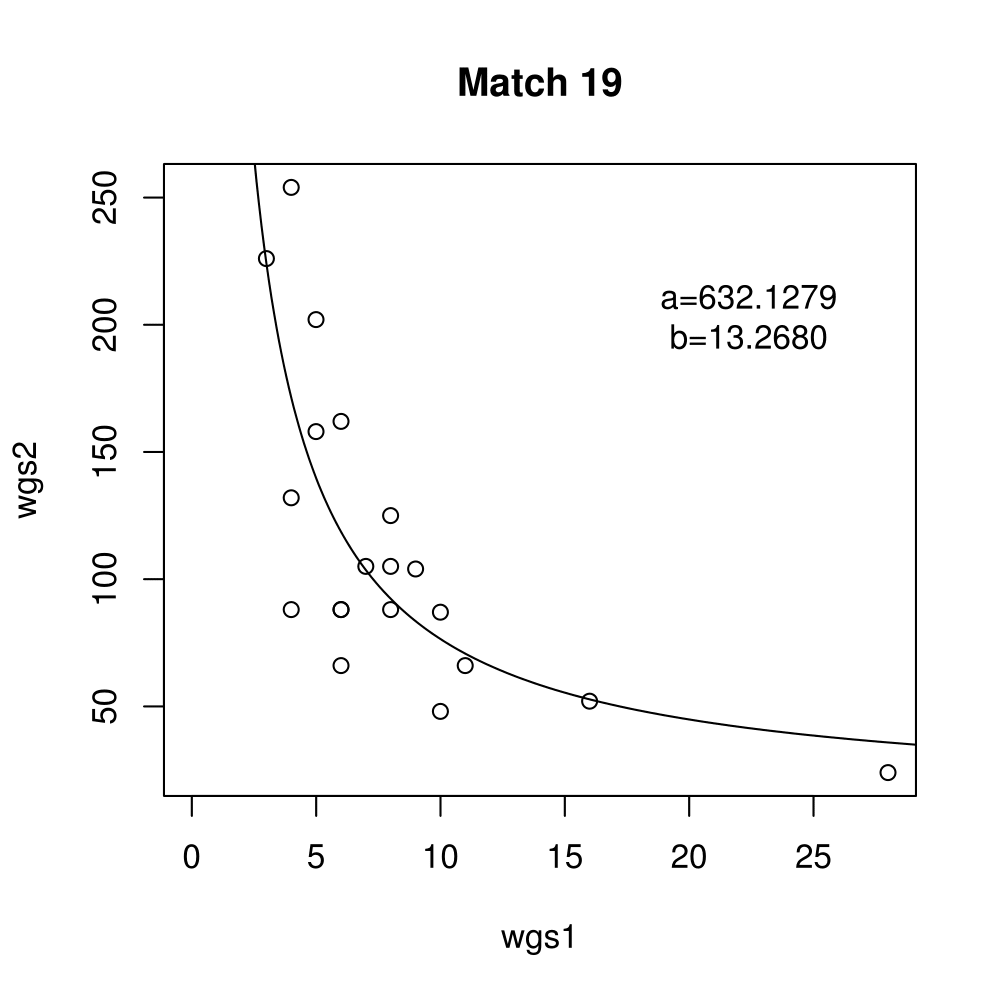
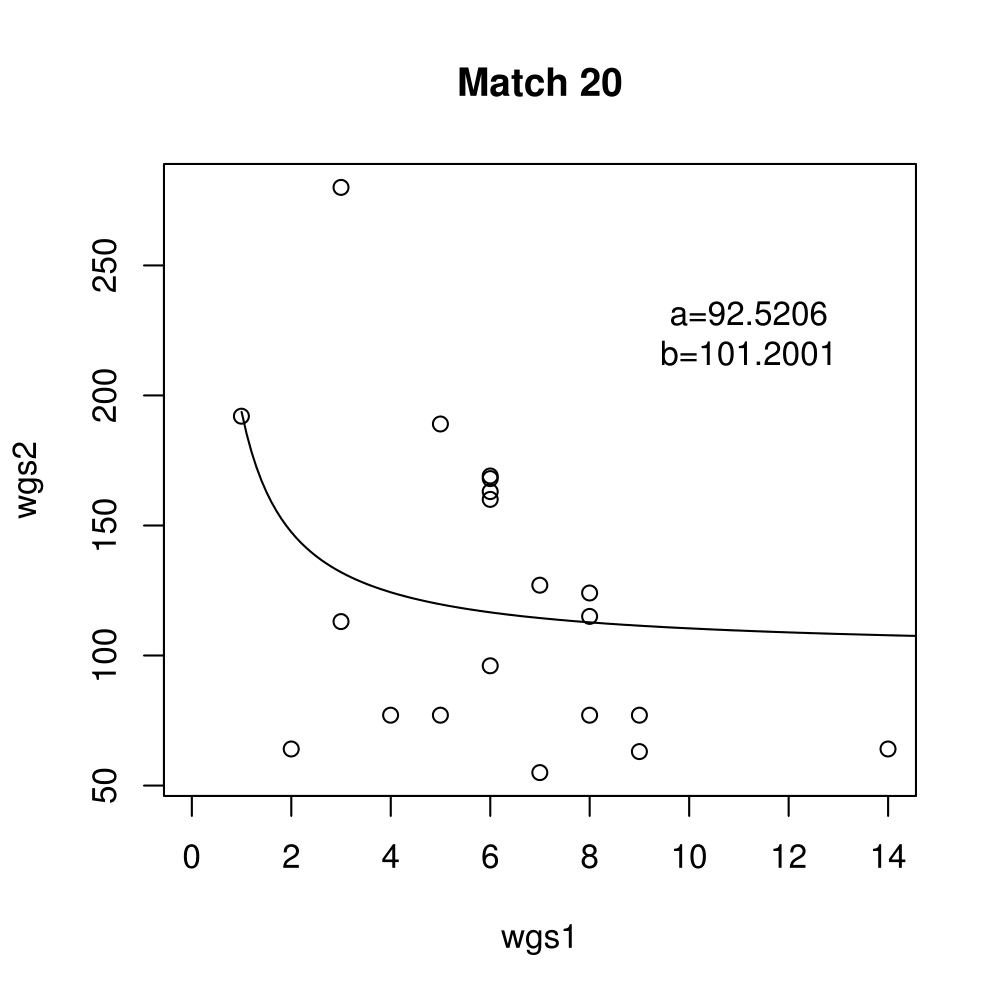
General purpose computing on graphics processing units, also known as GPGPU, enables massive parallelism by taking advantage of the Single Instruction Multiple Data (SIMD) architecture of the large number of cores found on modern graphics cards. A parameter critical to the performance of a GPGPU application is the local work group size, which controls how many work items are executed on a single compute unit. The ideal value minimises the memory access time by sharing (the slowest) access to the same area of global memory. While GPGPU vendors suggest default work group sizes based on generic benchmarks, finding the optimal local work group size for a given computation essentially remains as a trial-and-error task. This paper applies amortised optimisation to the (hidden) local work group size parameter in the GPGPU module of OpenCV. With repetitive use of OpenCV features, the amortised optimisation will guide the user to the local work group size best suited for the combination of user's graphics processing unit and the given GPGPU task.
Full Results
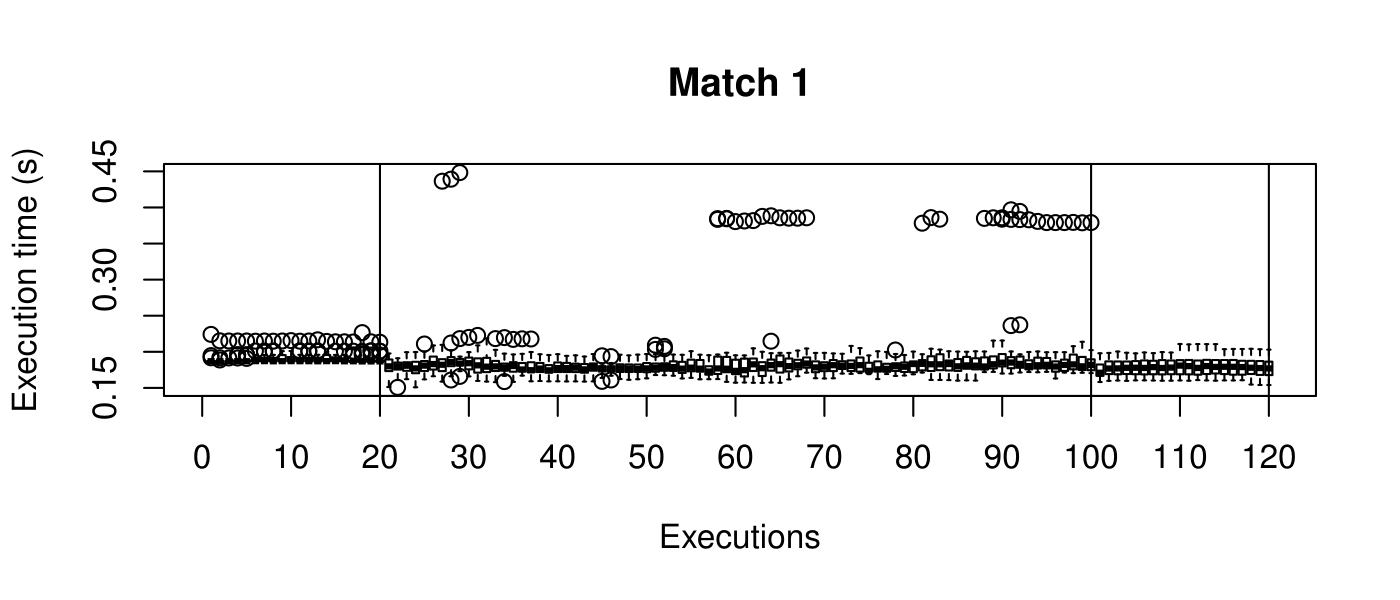
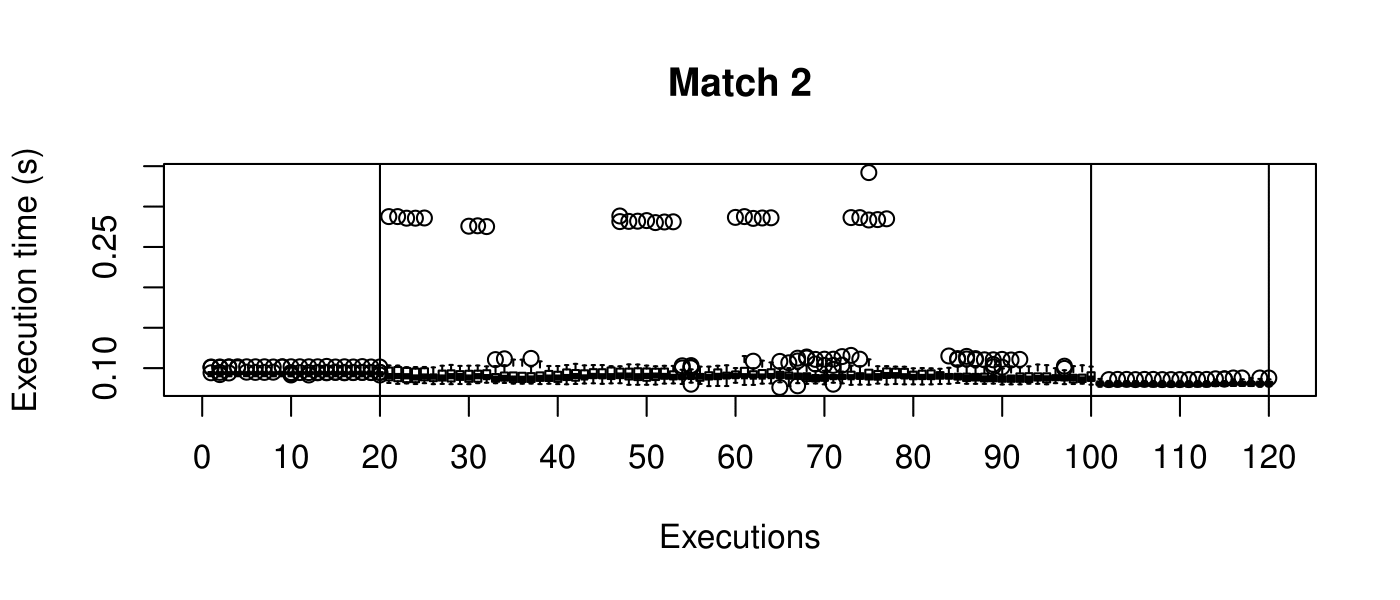
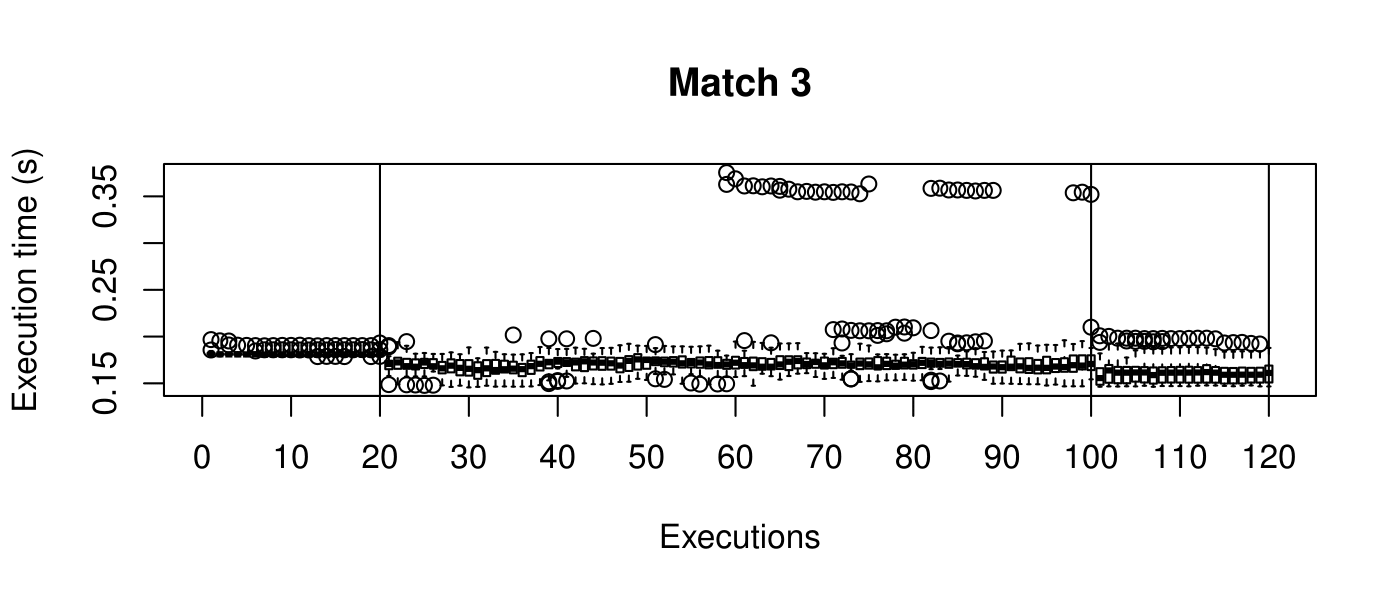
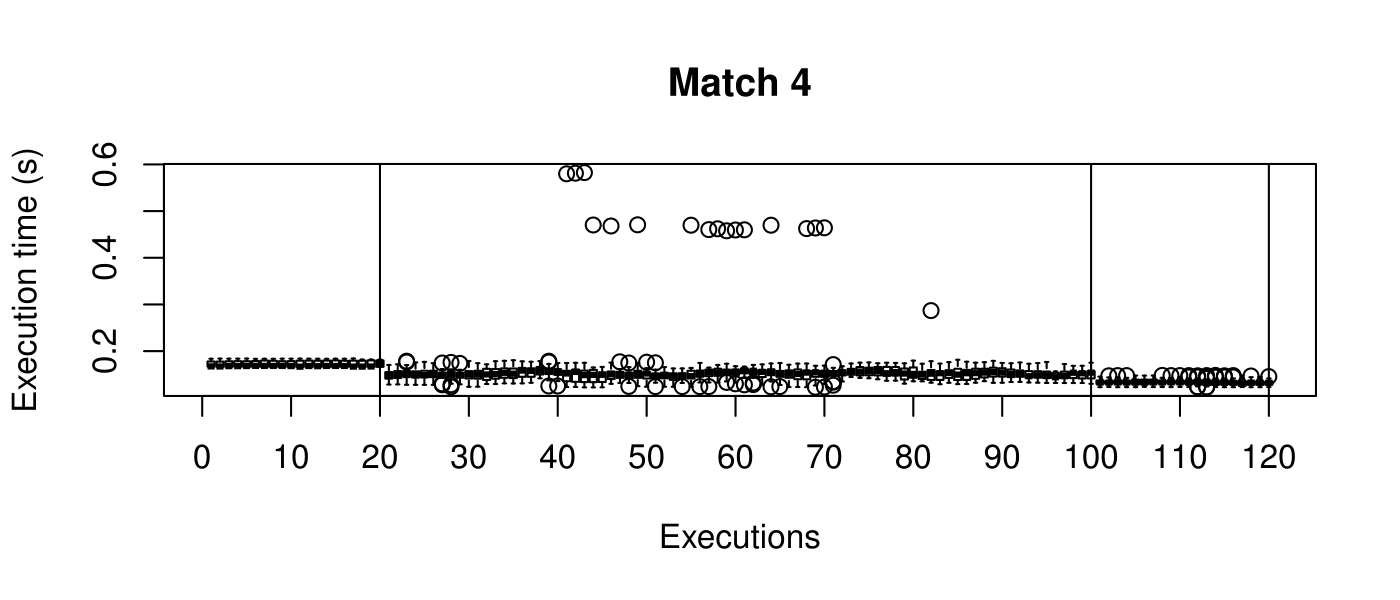
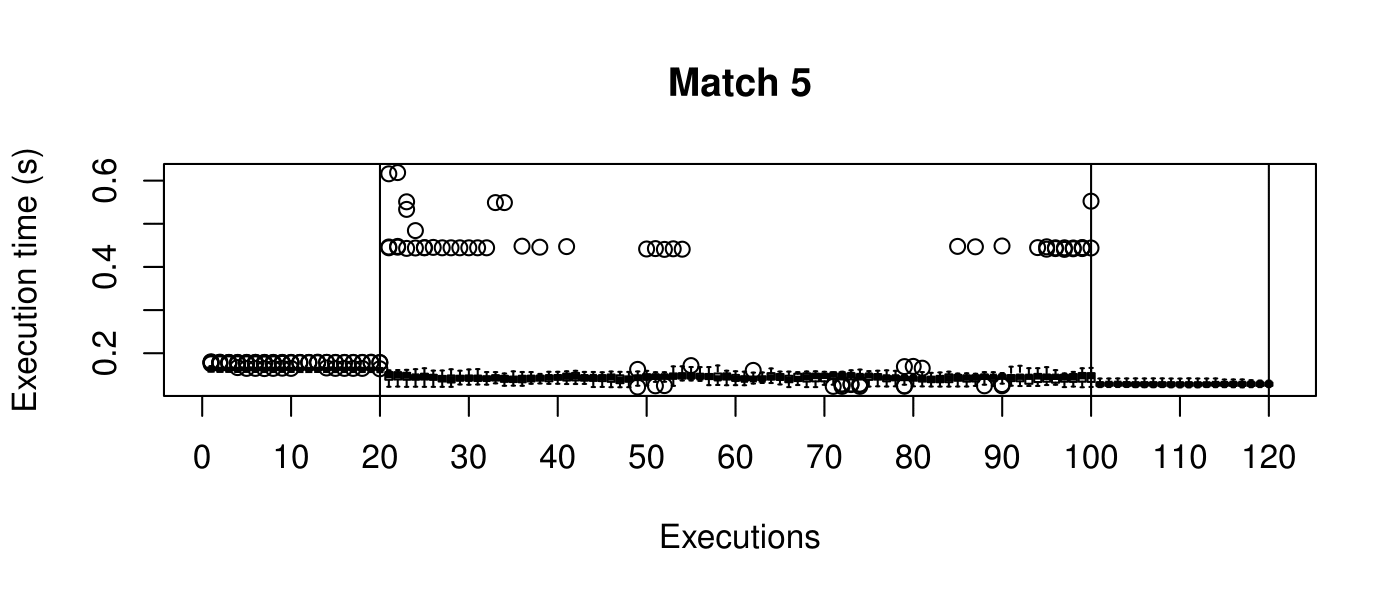
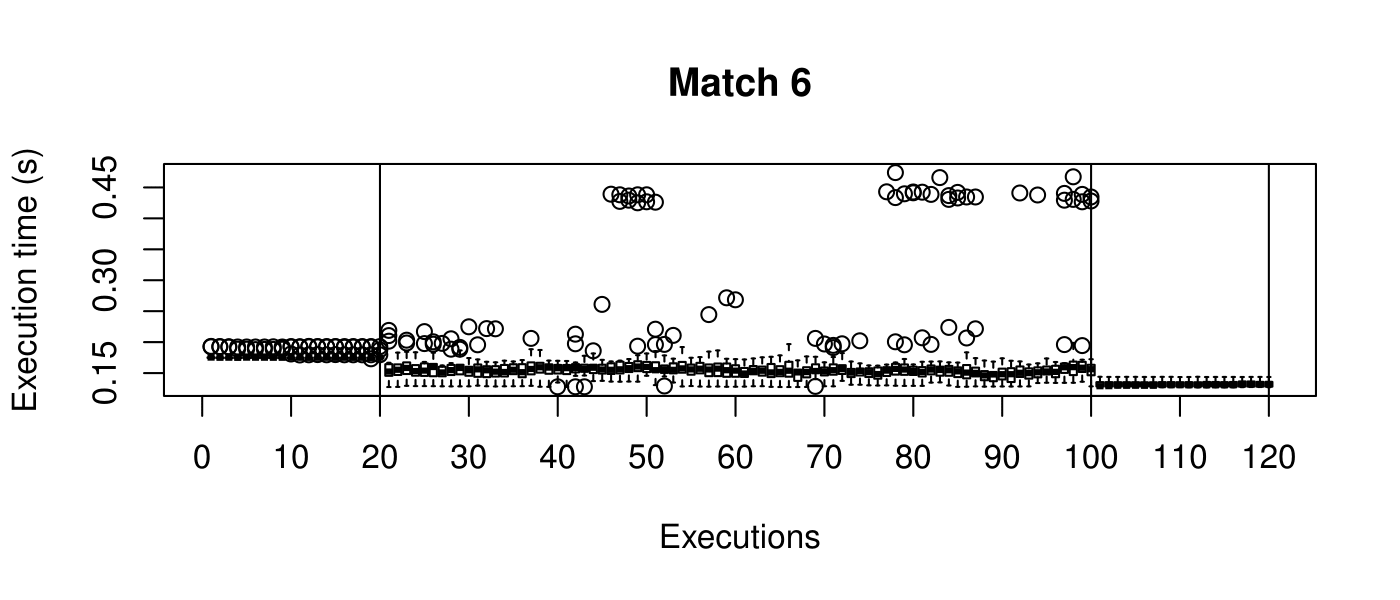
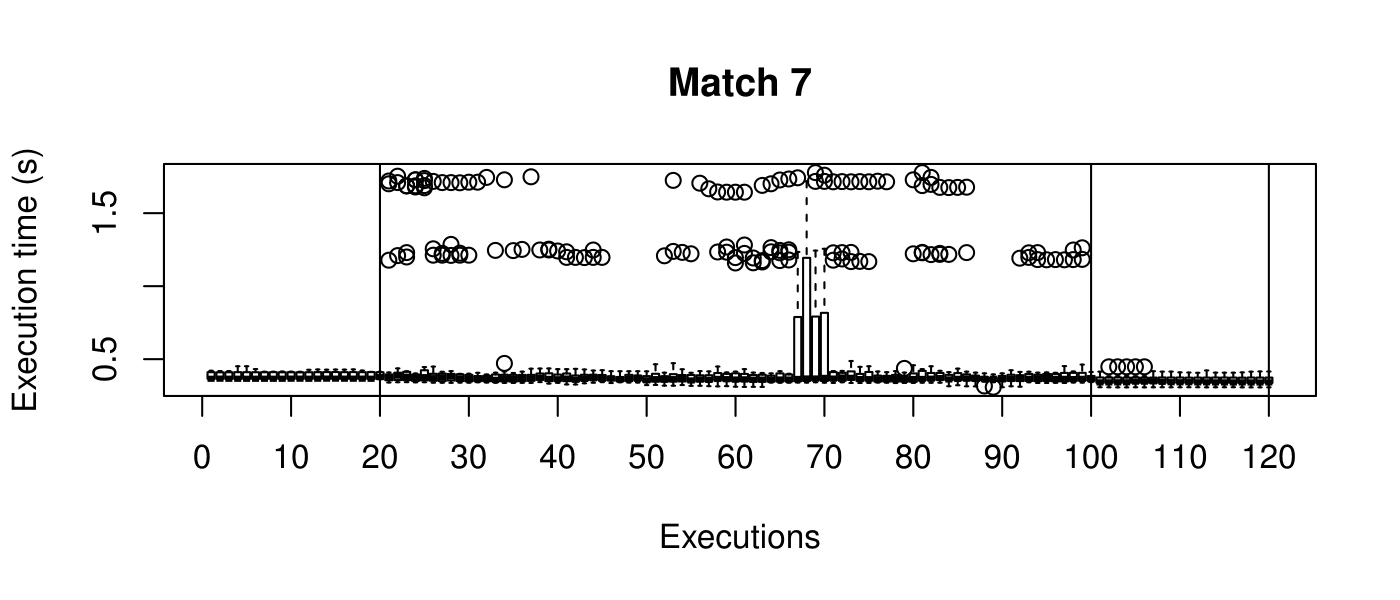
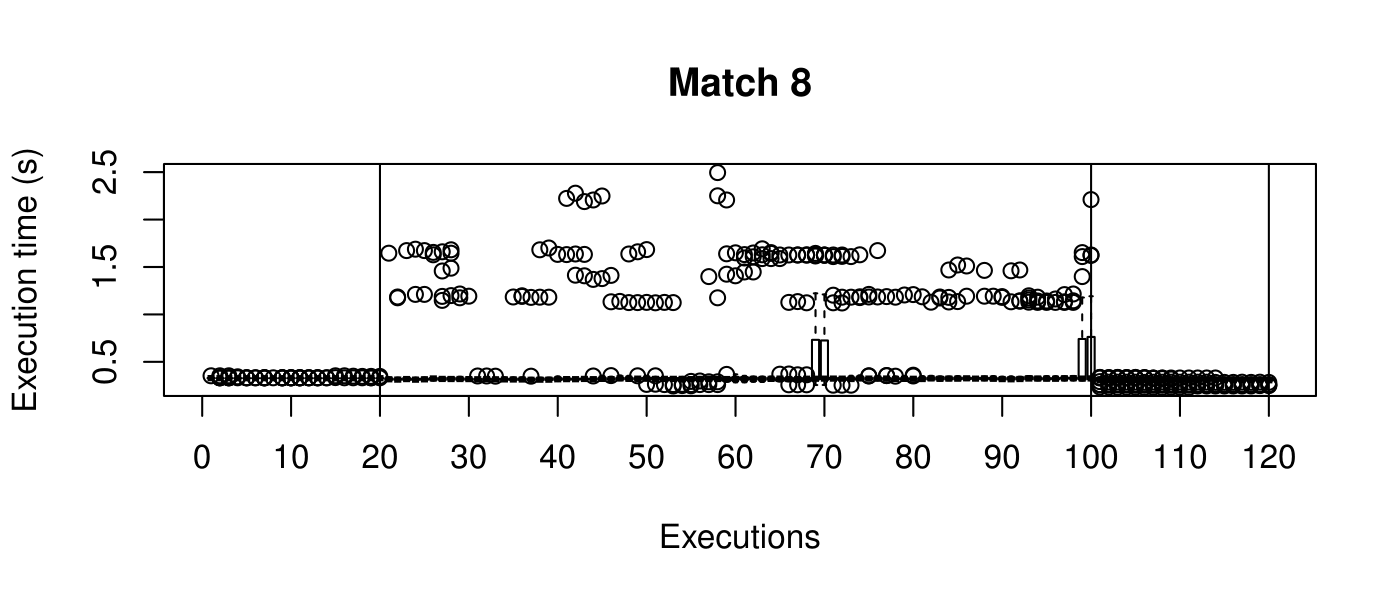
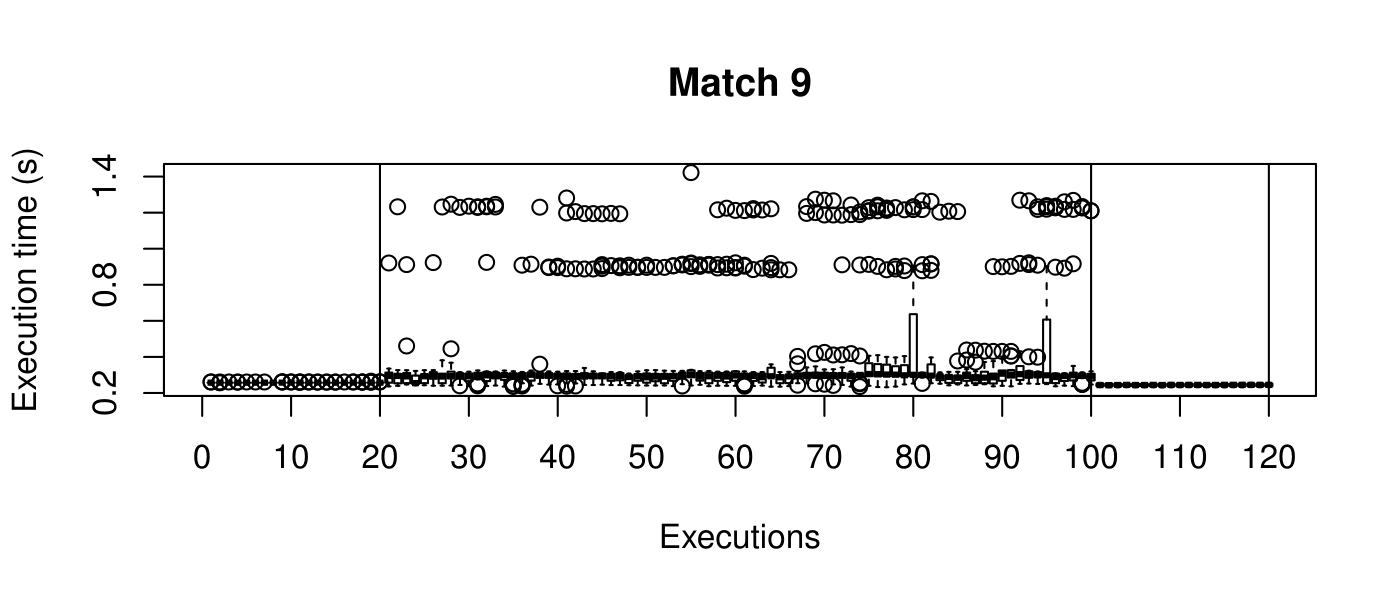
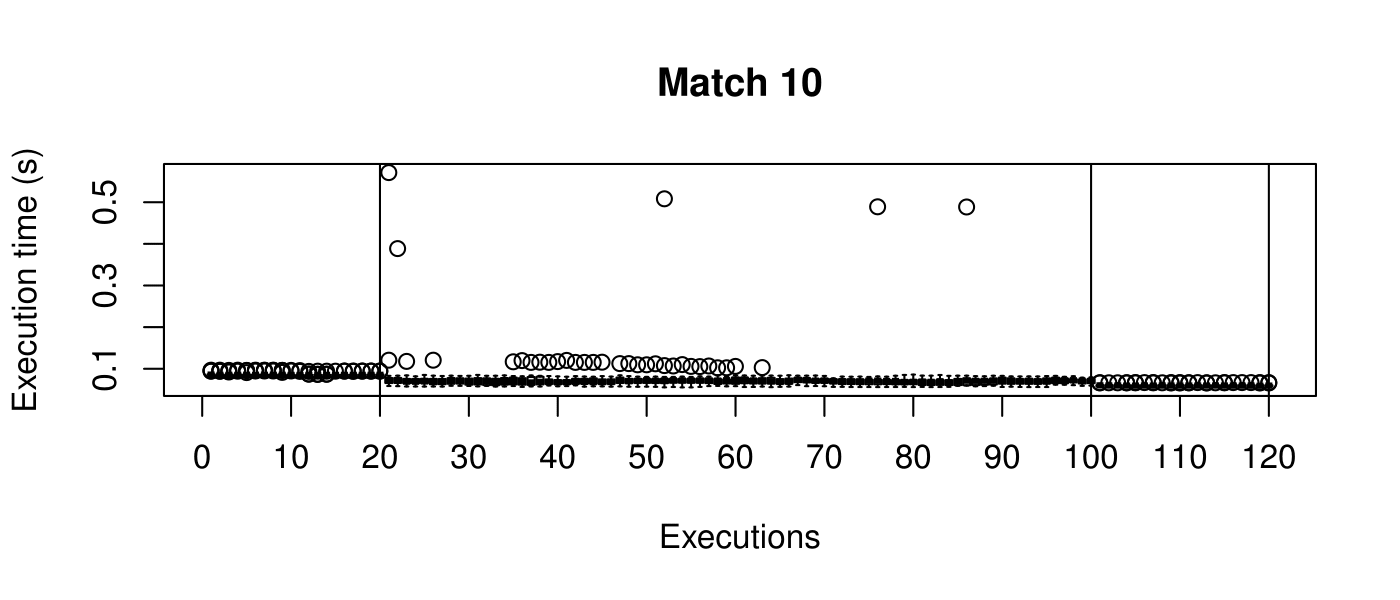
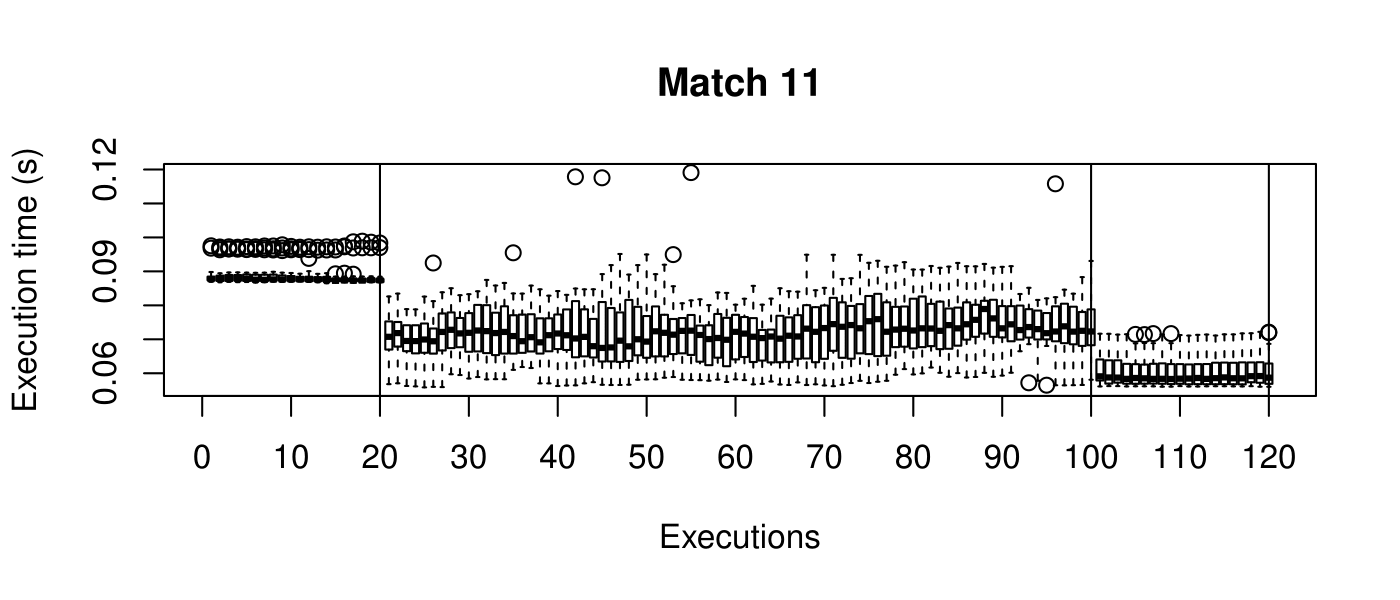
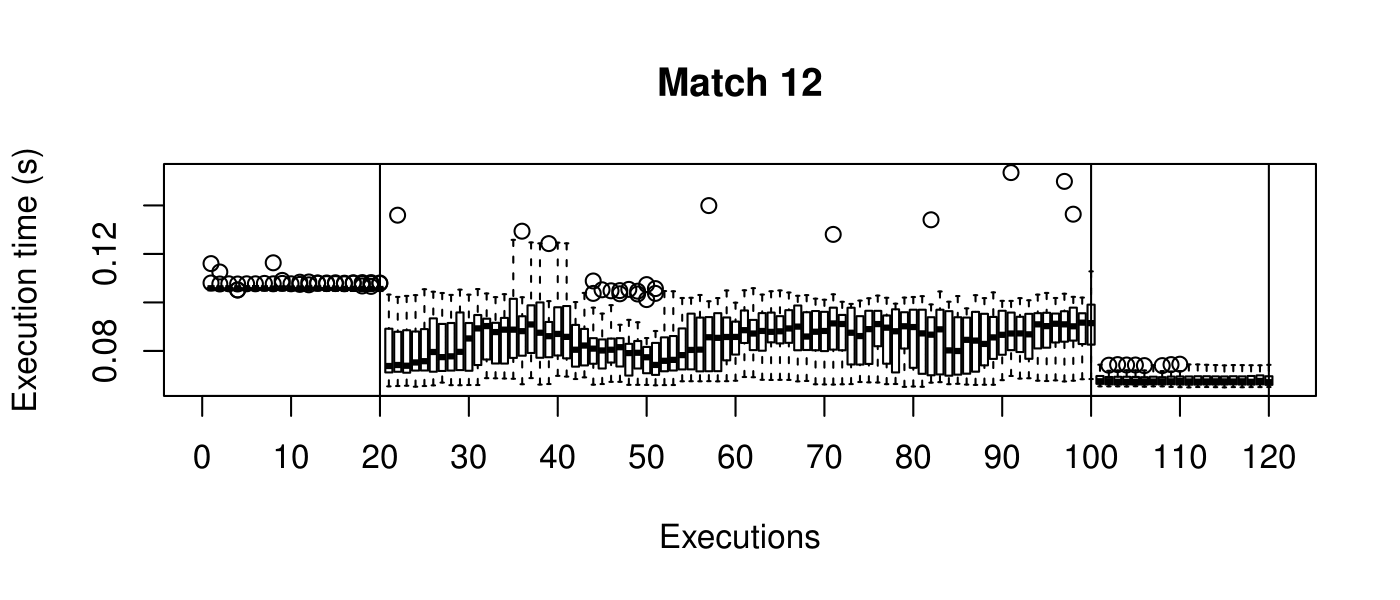
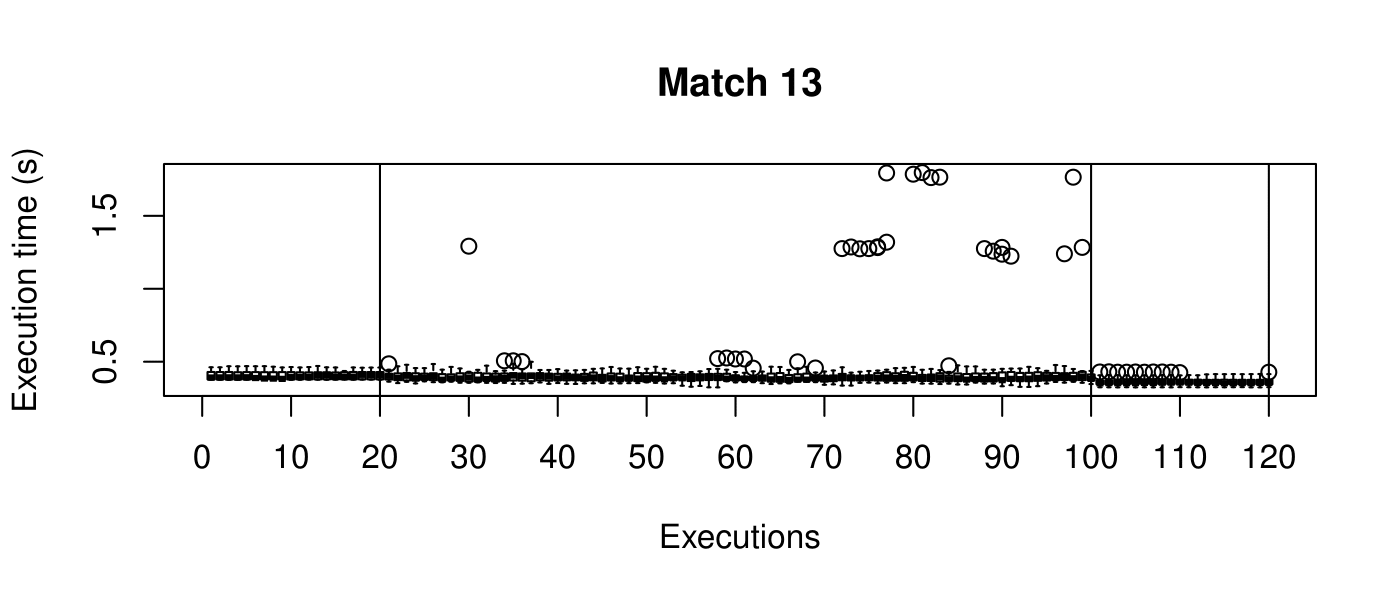
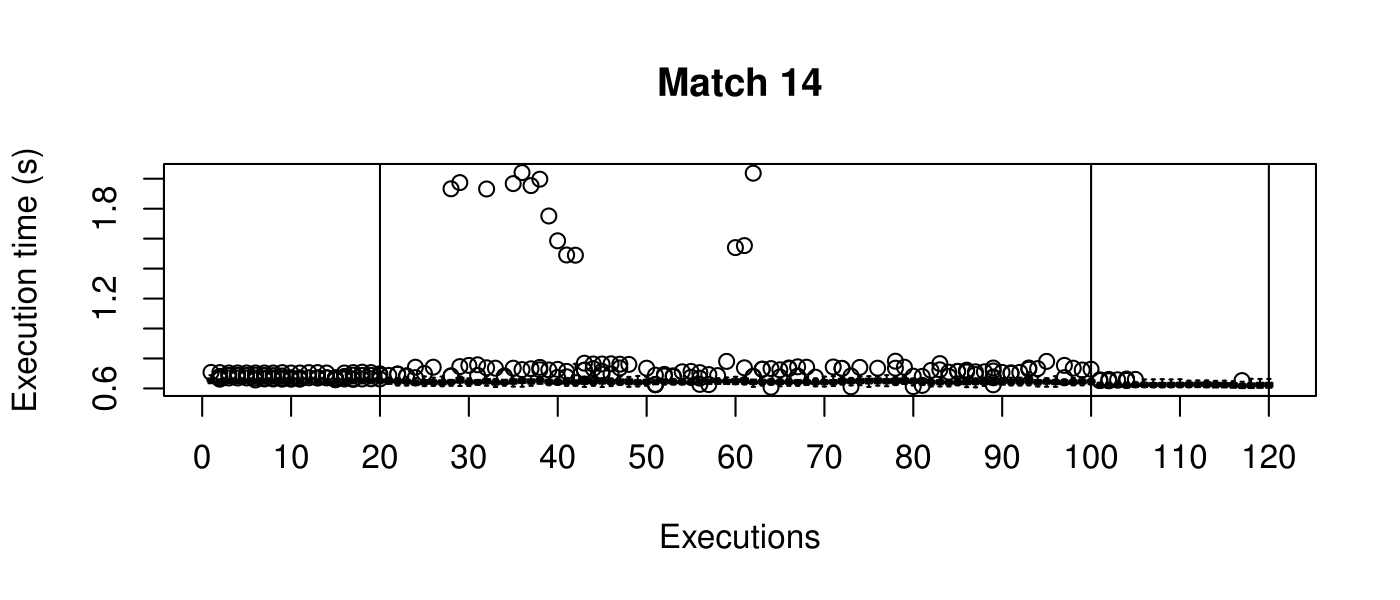
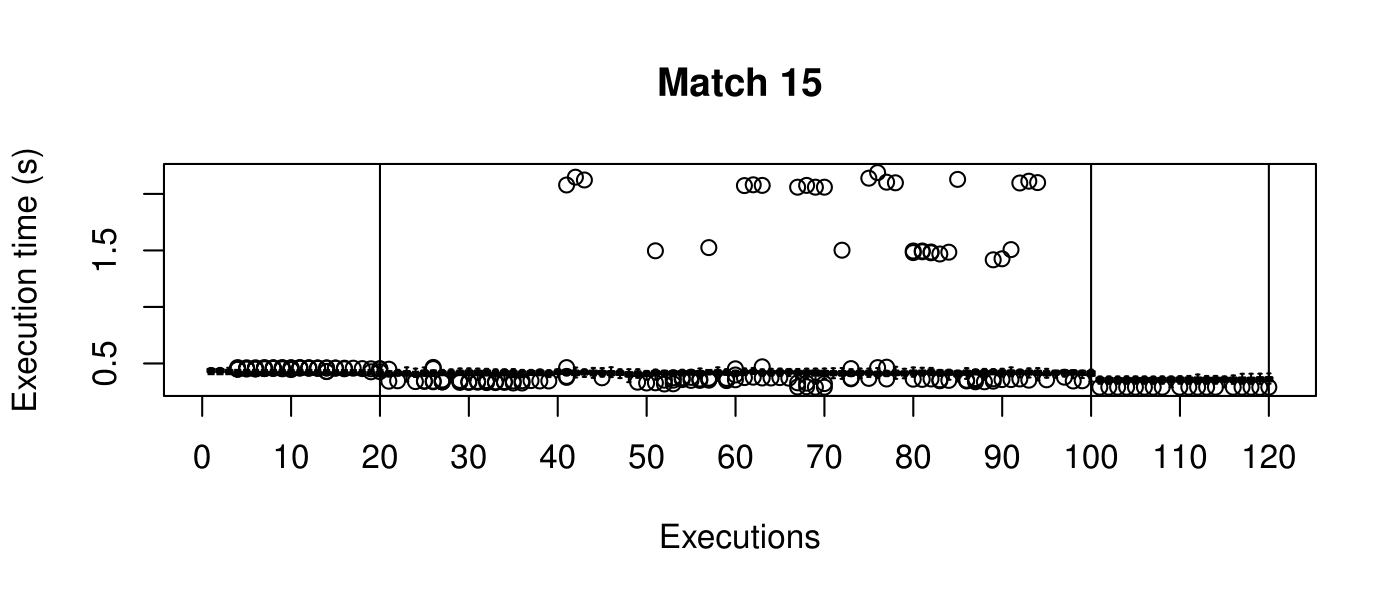
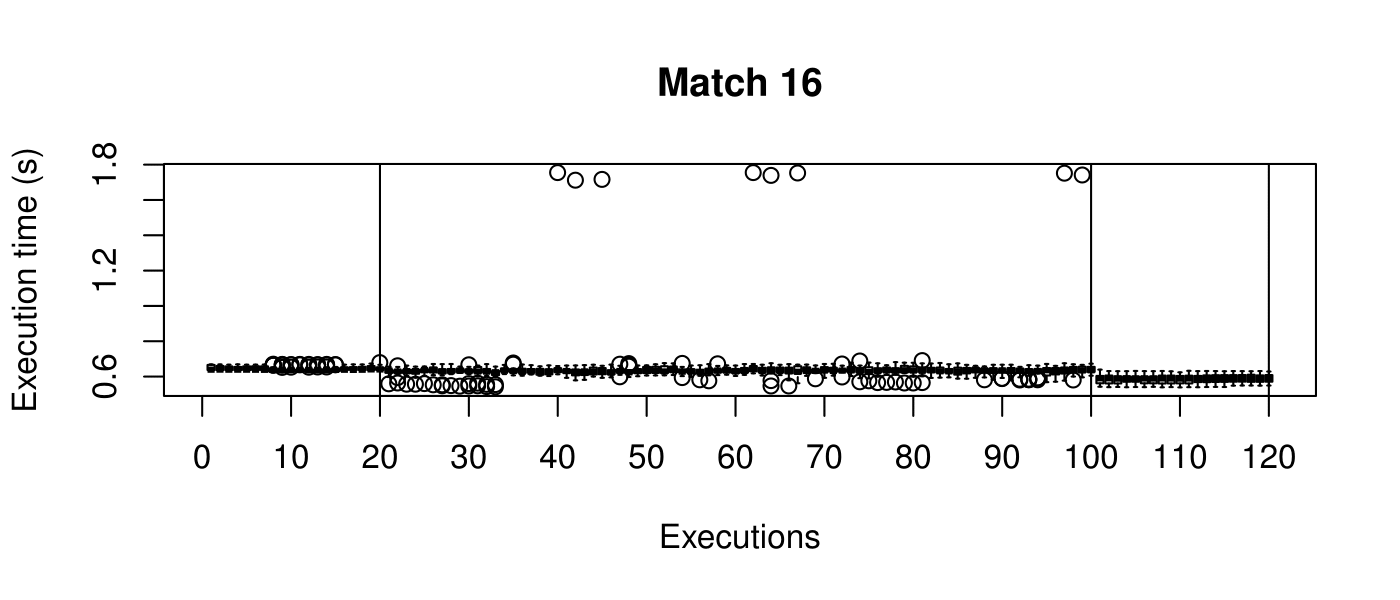
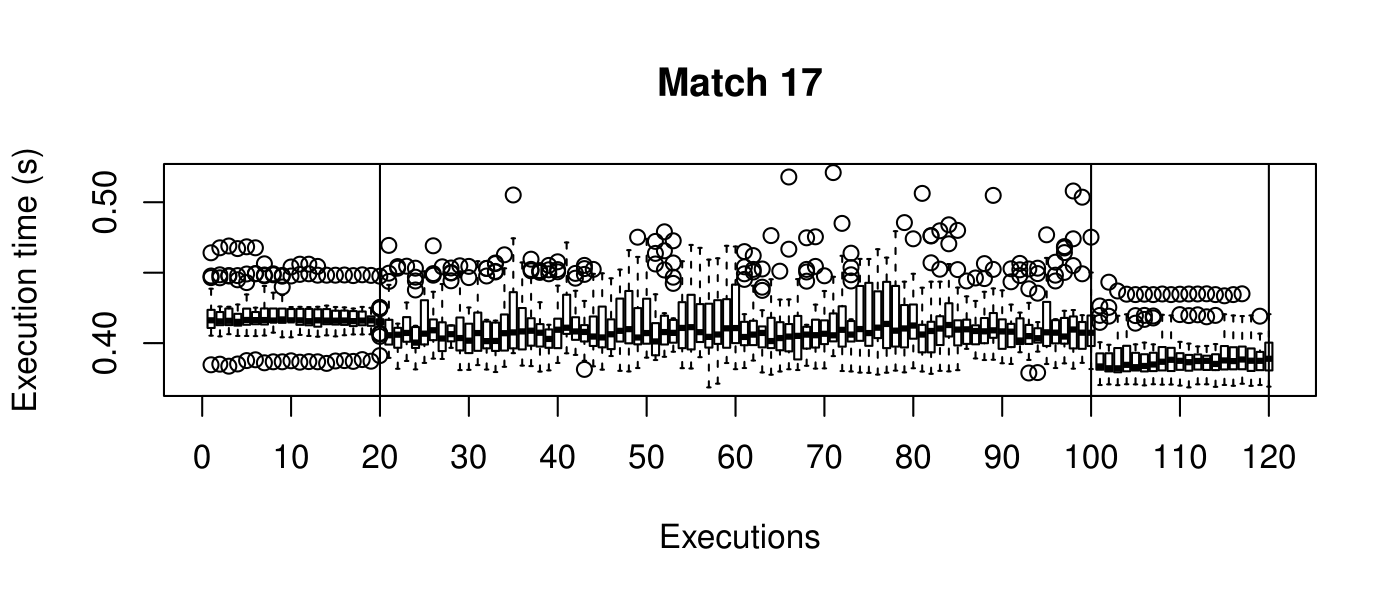
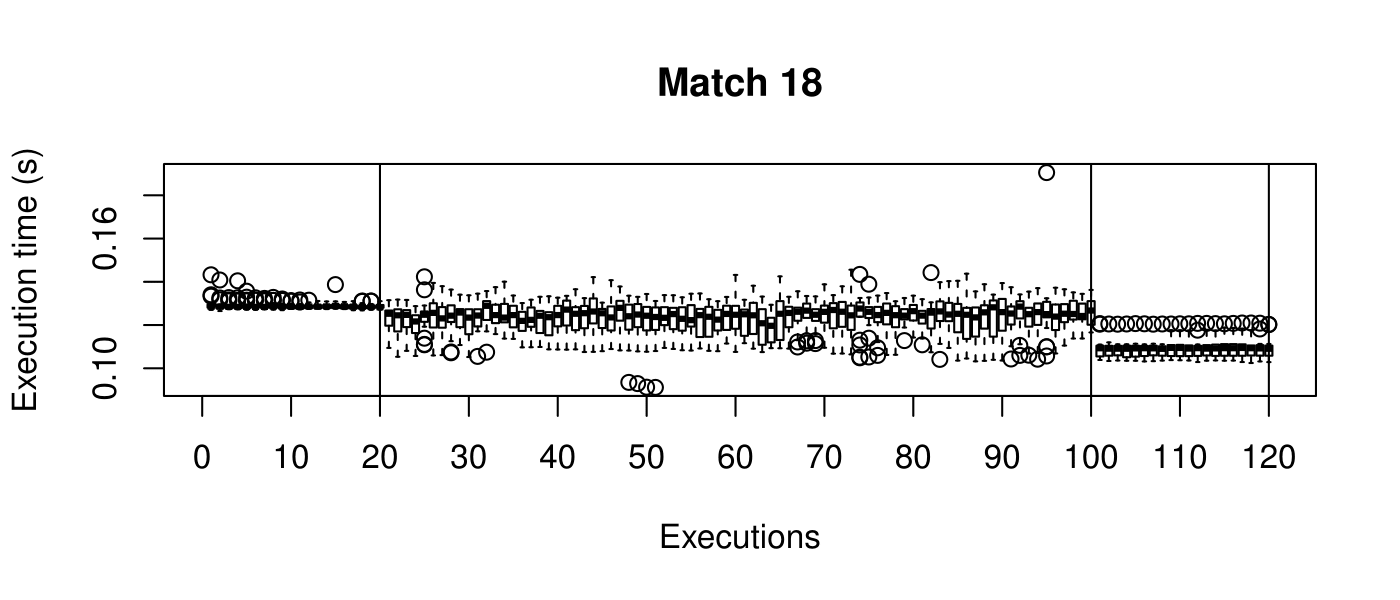
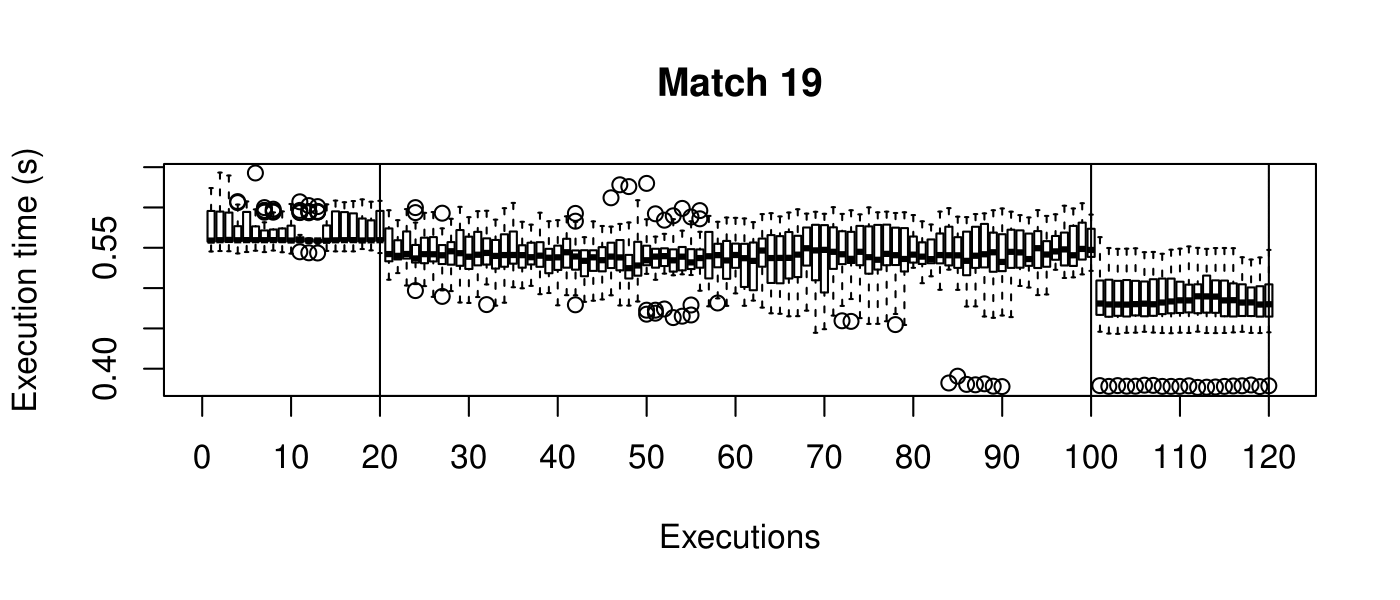
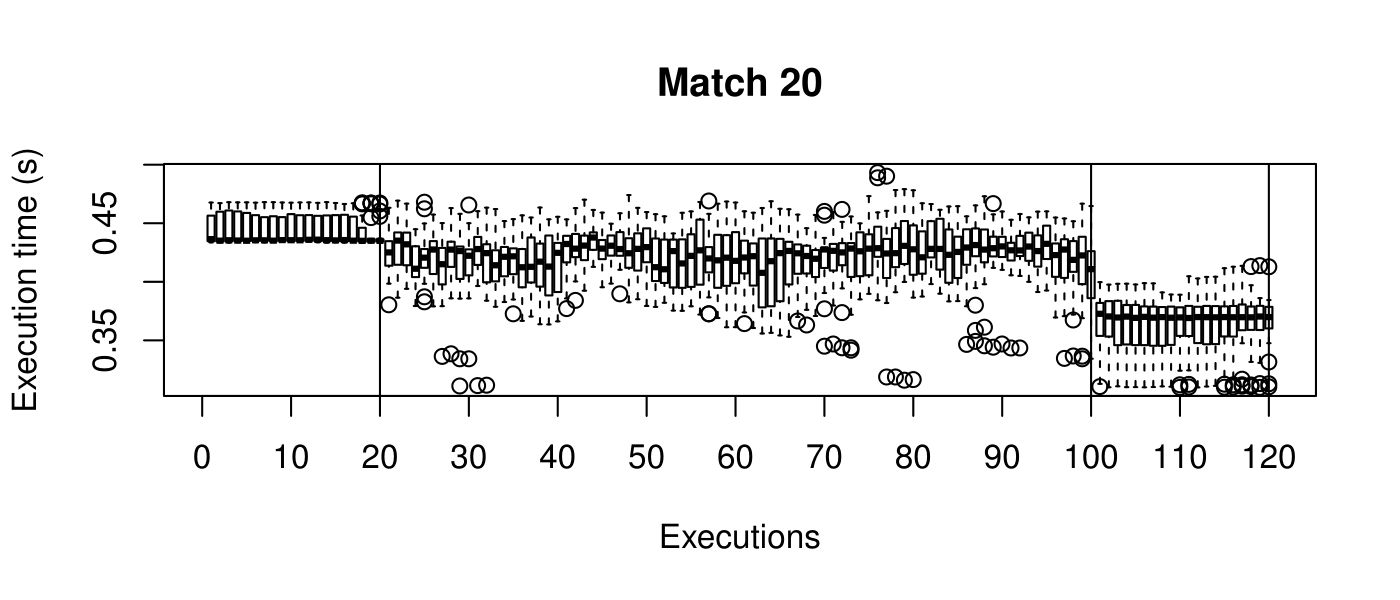
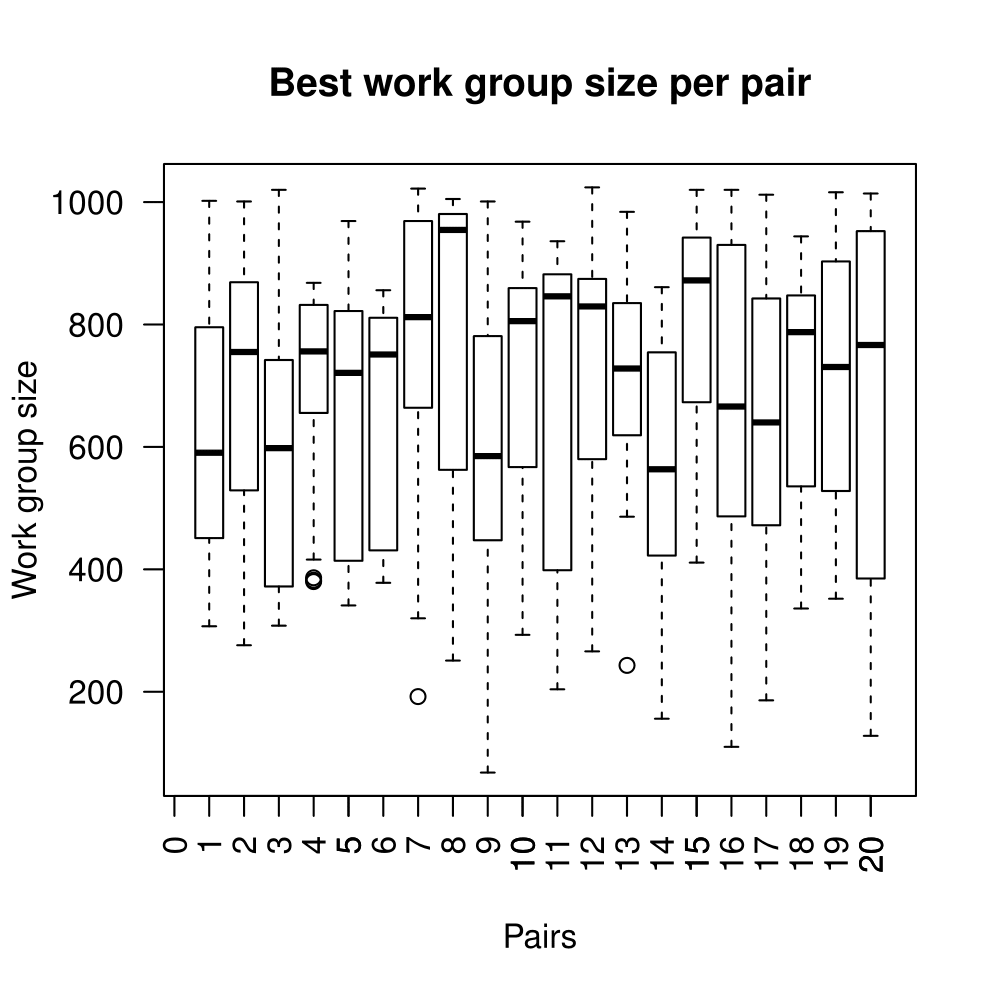
Our objective is to reduce the execution time. We used getTickCount and getTickFrequency, which are provided by OpenCV, to calculate execution time for each matching process. We counted the number of clock cycles had been passed during matching process and divided the number of clock cycles by clock tick frequency. This gives us execution time in seconds.
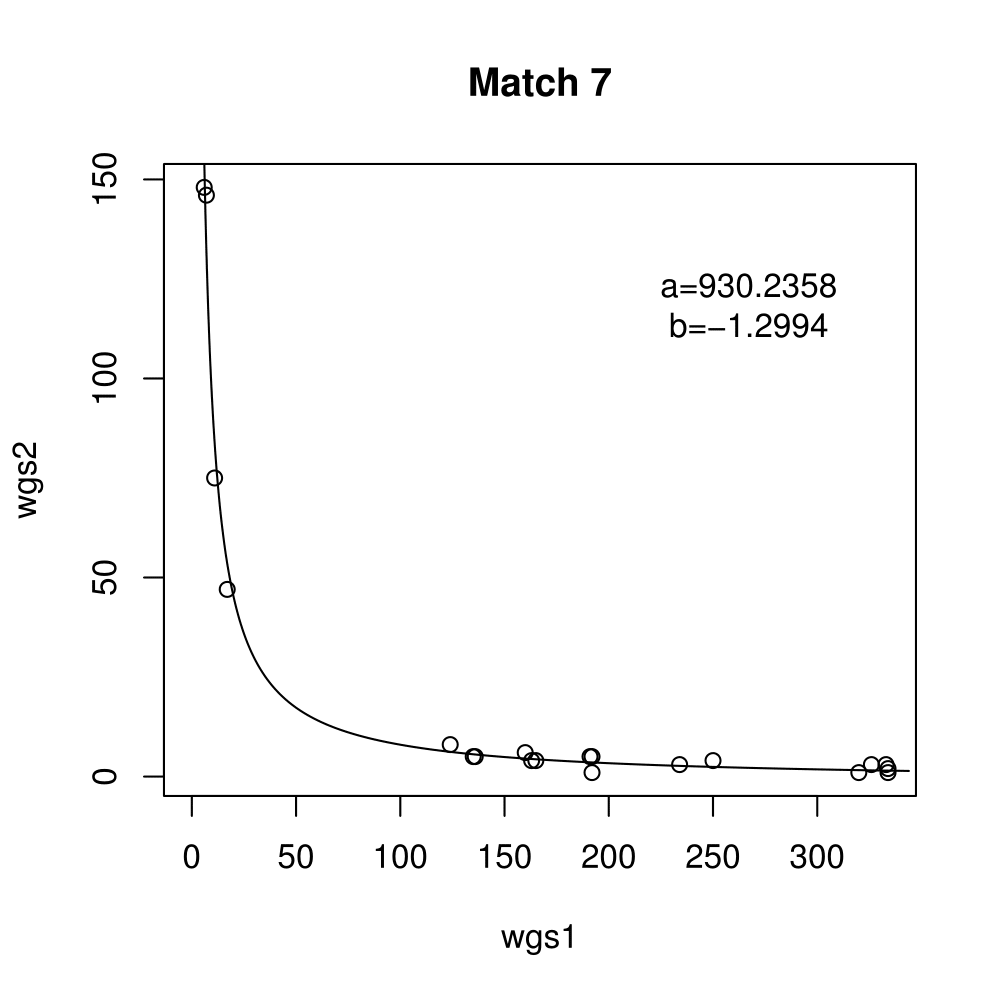
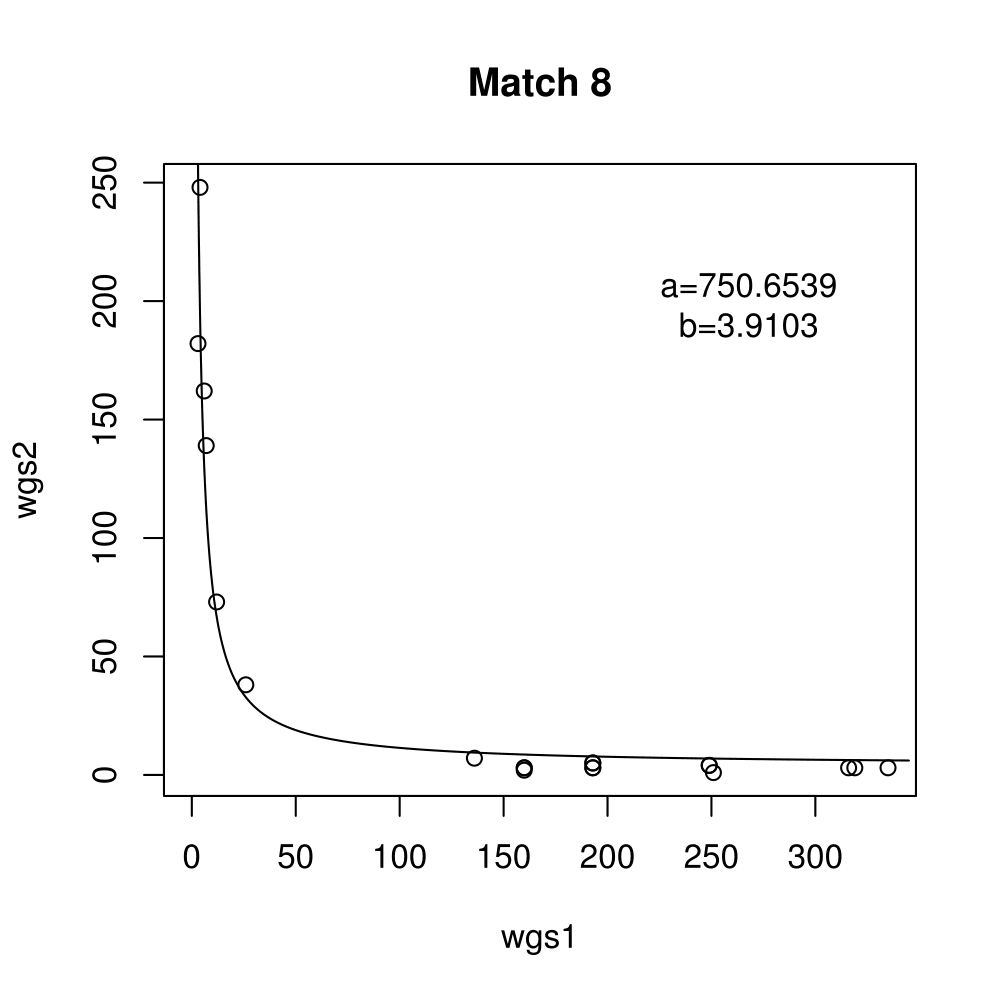
Boxplots show the results of 20 runs with OpenCV default setting, 80 runs with Amortised optimisation, and 20 runs with the best finding parameter values.
| Pair 01 | Pair 02 | Pair 03 | Pair 04 | Pair 05 |
| Pair 06 | Pair 07 | Pair 08 | Pair 09 | Pair 10 |
| Pair 11 | Pair 12 | Pair 13 | Pair 14 | Pair 15 |
| Pair 16 | Pair 17 | Pair 18 | Pair 19 | Pair 20 |