Our paper "Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction" has been accepted to ICSE 2023
This year, we are honored to have two manuscripts accepted to the 45th International Conference on Software Engineering, of which our paper [Large Language Models are Few-shot Testers: Exploring LLM-based General Bug Reproduction] is one. In this work, we first argue that automatic bug reproduction is a crucial task both in the context of automated debugging research and real-world developer activity. To solve this important problem, we propose LIBRO, a technique that leverages a large language model to generate a number of bug-reproducing tests given a prompt containing the bug report. The output of the large language model is post-processed and evaluated to predict which tests actually reproduce the bug at hand, instead of tests that always fail.
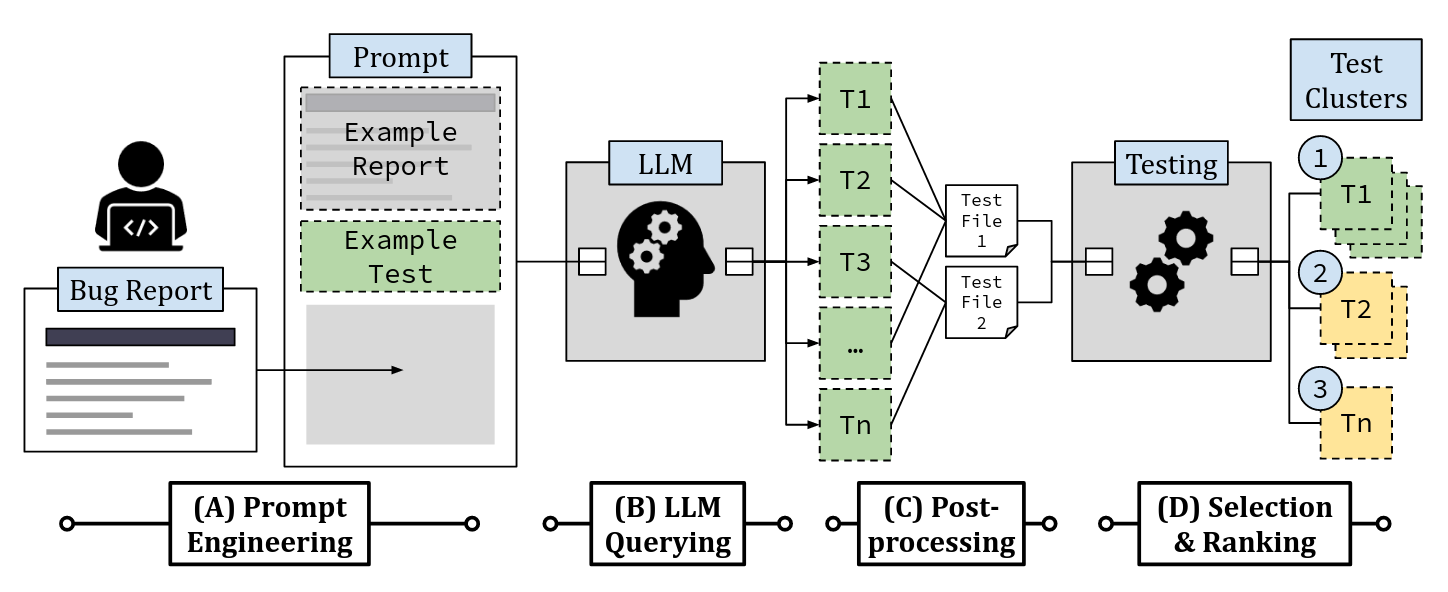
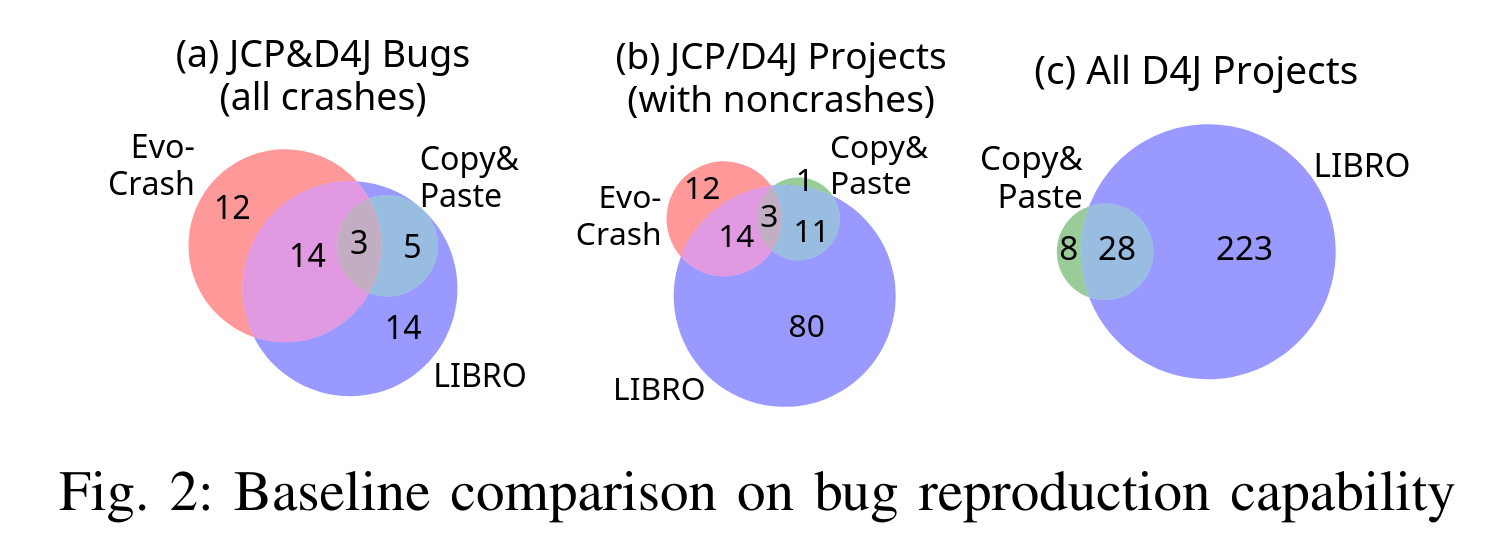
Overall, we find that one-third of bugs from the Defects4J benchmark can be reproduced using LIBRO, and that LIBRO significantly outperforms existing bug reproduction techniques that only focus on crashes:
If you are interested, you can find many more details in our preprint!